《Go Web编程》阅读笔记
1 环境配置
Go 是一种新的语言,一种并发的、带垃圾回收的、快速编译的语言。它具有以下特点:
它可以在一台计算机上用几秒钟的时间编译一个大型的 Go 程序。
Go 为软件构造提供了一种模型,它使依赖分析更加容易,且避免了大部分 C 风格 include 文件与库的开头。
- Go 是静态类型的语言,它的类型系统没有层级。因此用户不需要在定义类型之间的关系上花费时间,这样感觉起来比典型的面向对象语言更轻量级。
- Go 完全是垃圾回收型的语言,并为并发执行与通信提供了基本的支持。
- 按照其设计,Go 打算为多核机器上系统软件的构造提供一种方法。
Go 是一种编译型语言,它结合了解释型语言的游刃有余,动态类型语言的开发效率,以及静态类型的安全性。它也打算成为现代的,支持网络与多核计算的语言。要满足这些目标,需要解决一些语言上的问题:一个富有表达能力但轻量级的类型系统,并发与垃圾回收机制,严格的依赖规范等等。这些无法通过库或工具解决好,因此 Go 也就应运而生了。

1.1. 安装 Go
Go 源码安装
Go 1.5 彻底移除 C 代码,Runtime、Compiler、Linker 均由 Go 编写,实现自举。只需要安装了上一个版本,即可从源码安装。
在 Go 1.5 前,Go 的源代码中,有些部分是用 Plan 9 C 和 AT&T 汇编写的,因此假如你要想从源码安装,就必须安装 C 的编译工具。
1.2. GOPATH 与工作空间
GOPATH 来存放 Go 源码,Go 的可运行文件,以及相应的编译之后的包文件。所以这个目录下面有三个子目录:src、bin、pkg
GOPATH 环境变量现在有一个默认值,如果它没有被设置。 它在 Unix 上默认为 $HOME/go,在 Windows 上默认为 %USERPROFILE%/go。
GOPATH 设置
GOPATH 允许多个目录,当有多个目录时,请注意分隔符,多个目录的时候 Windows 是分号,Linux 系统是冒号,当有多个 GOPATH 时,默认会将 go get 的内容放在第一个目录下。
以上 $GOPATH 目录约定有三个子目录:
- src 存放源代码(比如:.go .c .h .s 等)
- pkg 编译后生成的文件(比如:.a)
- bin 编译后生成的可执行文件(为了方便,可以把此目录加入到 $PATH 变量中,如果有多个 gopath,那么使用 ${GOPATH//://bin:}/bin 添加所有的 bin 目录)
- 以后我所有的例子都是以 mygo 作为我的 gopath 目录
代码目录结构规划
GOPATH 下的 src 目录就是接下来开发程序的主要目录,所有的源码都是放在这个目录下面,那么一般我们的做法就是一个目录一个项目,例如: $GOPATH/src/mymath 表示 mymath 这个应用包或者可执行应用,这个根据 package 是 main 还是其他来决定,main 的话就是可执行应用,其他的话就是应用包,这个会在后续详细介绍 package。
所以当新建应用或者一个代码包时都是在 src 目录下新建一个文件夹,文件夹名称一般是代码包名称,当然也允许多级目录,例如在 src 下面新建了目录 $GOPATH/src/github.com/astaxie/beedb 那么这个包路径就是 “github.com/astaxie/beedb”,包名称是最后一个目录 beedb
注意:一般建议 package 的名称和目录名保持一致
下面我就以mymath为例来讲述如何编写应用包,执行如下代码
cd $GOPATH/src
mkdir mymath新建文件sqrt.go,内容如下
// $GOPATH/src/mymath/sqrt.go源码如下:
package mymath
func Sqrt(x float64) float64 {
z := 0.0
for i := 0; i < 1000; i++ {
z -= (z*z - x) / (2 * x)
}
return z
}编译应用
1、只要进入对应的应用包目录,然后执行go install,就可以安装了
2、在任意的目录执行如下代码go install mymath
安装完之后,我们可以进入如下目录
cd $GOPATH/pkg/${GOOS}_${GOARCH}
//可以看到如下文件
mymath.a这个.a文件是应用包,那么我们如何进行调用呢?
接下来我们新建一个应用程序来调用这个应用包
新建应用包mathapp
cd $GOPATH/src
mkdir mathapp
cd mathapp
vim main.go$GOPATH/src/mathapp/main.go源码:
package main
import (
"mymath"
"fmt"
)
func main() {
fmt.Printf("Hello, world. Sqrt(2) = %v\n", mymath.Sqrt(2))
}如何编译程序呢?进入该应用目录,然后执行go build,那么在该目录下面会生成一个mathapp的可执行文件
./mathapp输出如下内容
Hello, world. Sqrt(2) = 1.414213562373095如何安装该应用,进入该目录执行go install,那么在$GOPATH/bin/下增加了一个可执行文件mathapp, 还记得前面我们把$GOPATH/bin加到我们的PATH里面了,这样可以在命令行输入如下命令就可以执行
mathapp获取远程包
go语言有一个获取远程包的工具就是go get,目前go get支持多数开源社区(例如:github、googlecode、bitbucket、Launchpad)
go get github.com/astaxie/beedbgo get -u 参数可以自动更新包,而且当go get的时候会自动获取该包依赖的其他第三方包
通过这个命令可以获取相应的源码,对应的开源平台采用不同的源码控制工具,例如github采用git、googlecode采用hg,所以要想获取这些源码,必须先安装相应的源码控制工具
1.3 Go 命令
略
其它命令
go还提供了其它很多的工具,例如下面的这些工具
go version 查看go当前的版本
go env 查看当前go的环境变量
go list 列出当前全部安装的package
go run 编译并运行Go程序3 Web基础

3.1 Web工作方式
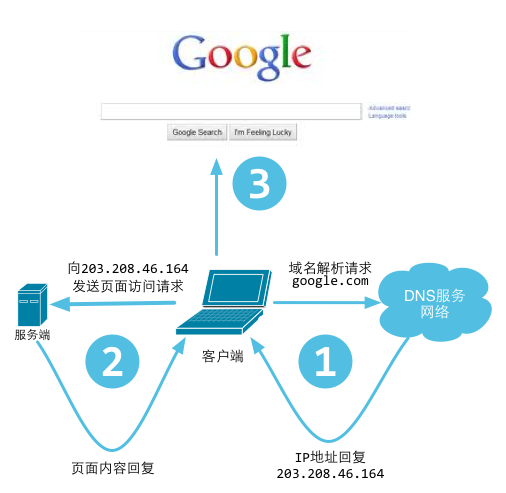
对于普通的上网过程,系统其实是这样做的:浏览器本身是一个客户端,当你输入URL的时候,首先浏览器会去请求DNS服务器,通过DNS获取相应的域名对应的IP,然后通过IP地址找到IP对应的服务器后,要求建立TCP连接,等浏览器发送完HTTP Request(请求)包后,服务器接收到请求包之后才开始处理请求包,服务器调用自身服务,返回HTTP Response(响应)包;客户端收到来自服务器的响应后开始渲染这个Response包里的主体(body),等收到全部的内容随后断开与该服务器之间的TCP连接。
一个Web服务器也被称为HTTP服务器,它通过HTTP协议与客户端通信。这个客户端通常指的是Web浏览器(其实手机端客户端内部也是浏览器实现的)。
Web服务器的工作原理可以简单地归纳为:
- 客户机通过TCP/IP协议建立到服务器的TCP连接
- 客户端向服务器发送HTTP协议请求包,请求服务器里的资源文档
- 服务器向客户机发送HTTP协议应答包,如果请求的资源包含有动态语言的内容,那么服务器会调用动态语言的解释引擎负责处理“动态内容”,并将处理得到的数据返回给客户端
- 客户机与服务器断开。由客户端解释HTML文档,在客户端屏幕上渲染图形结果
URL和DNS解析
URL(Uniform Resource Locator)是“统一资源定位符”的英文缩写,用于描述一个网络上的资源, 基本格式如下
scheme://host[:port#]/path/.../[?query-string][#anchor]
scheme 指定低层使用的协议(例如:http, https, ftp)
host HTTP服务器的IP地址或者域名
port# HTTP服务器的默认端口是80,这种情况下端口号可以省略。如果使用了别的端口,必须指明,例如 http://www.cnblogs.com:8080/
path 访问资源的路径
query-string 发送给http服务器的数据
anchor 锚DNS(Domain Name System)是“域名系统”的英文缩写,是一种组织成域层次结构的计算机和网络服务命名系统,它用于TCP/IP网络,它从事将主机名或域名转换为实际IP地址的工作。DNS就是这样的一位“翻译官”,它的基本工作原理可用下图来表示。
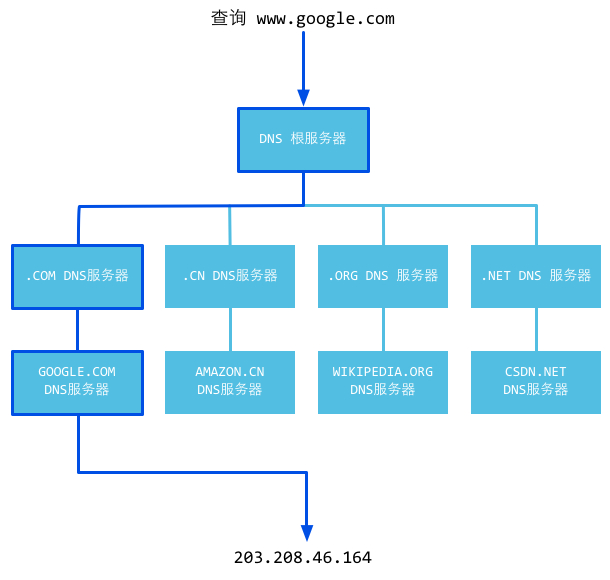
更详细的DNS解析的过程如下,这个过程有助于我们理解DNS的工作模式
- 在浏览器中输入www.qq.com域名,操作系统会先检查自己本地的hosts文件是否有这个网址映射关系,如果有,就先调用这个IP地址映射,完成域名解析。
- 如果hosts里没有这个域名的映射,则查找本地DNS解析器缓存,是否有这个网址映射关系,如果有,直接返回,完成域名解析。
- 如果hosts与本地DNS解析器缓存都没有相应的网址映射关系,首先会找TCP/IP参数中设置的首选DNS服务器,在此我们叫它本地DNS服务器,此服务器收到查询时,如果要查询的域名,包含在本地配置区域资源中,则返回解析结果给客户机,完成域名解析,此解析具有权威性。
- 如果要查询的域名,不由本地DNS服务器区域解析,但该服务器已缓存了此网址映射关系,则调用这个IP地址映射,完成域名解析,此解析不具有权威性。
- 如果本地DNS服务器本地区域文件与缓存解析都失效,则根据本地DNS服务器的设置(是否设置转发器)进行查询,如果未用转发模式,本地DNS就把请求发至 “根DNS服务器”,“根DNS服务器”收到请求后会判断这个域名(.com)是谁来授权管理,并会返回一个负责该顶级域名服务器的一个IP。本地DNS服务器收到IP信息后,将会联系负责.com域的这台服务器。这台负责.com域的服务器收到请求后,如果自己无法解析,它就会找一个管理.com域的下一级DNS服务器地址(qq.com)给本地DNS服务器。当本地DNS服务器收到这个地址后,就会找qq.com域服务器,重复上面的动作,进行查询,直至找到www.qq.com主机。
- 如果用的是转发模式,此DNS服务器就会把请求转发至上一级DNS服务器,由上一级服务器进行解析,上一级服务器如果不能解析,或找根DNS或把转请求转至上上级,以此循环。不管是本地DNS服务器用是是转发,还是根提示,最后都是把结果返回给本地DNS服务器,由此DNS服务器再返回给客户机。
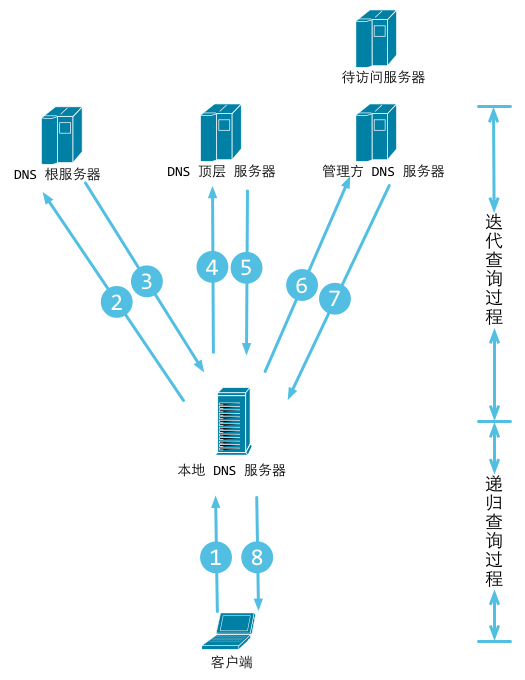
DNS解析的整个流程(完成若干次迭代查询,即,问询者角色不变,但反复更替问询对象)
通过上面的步骤,我们最后获取的是IP地址,也就是浏览器最后发起请求的时候是基于IP来和服务器做信息交互的。
HTTP协议详解
HTTP是一种让Web服务器与浏览器(客户端)通过Internet发送与接收数据的协议,它建立在TCP协议之上,一般采用TCP的80端口。它是一个请求、响应协议—客户端发出一个请求,服务器响应这个请求。在HTTP中,客户端总是通过建立一个连接与发送一个HTTP请求来发起一个事务。服务器不能主动去与客户端联系,也不能给客户端发出一个回调连接。客户端与服务器端都可以提前中断一个连接。例如,当浏览器下载一个文件时,你可以通过点击“停止”键来中断文件的下载,关闭与服务器的HTTP连接。
HTTP协议是无状态的,同一个客户端的这次请求和上次请求是没有对应关系,对HTTP服务器来说,它并不知道这两个请求是否来自同一个客户端。为了解决这个问题, Web程序引入了Cookie机制来维护连接的可持续状态。
HTTP协议是建立在TCP协议之上的,因此TCP攻击一样会影响HTTP的通讯,例如比较常见的一些攻击:SYN Flood是当前最流行的DoS(拒绝服务攻击)与DdoS(分布式拒绝服务攻击)的方式之一,这是一种利用TCP协议缺陷,发送大量伪造的TCP连接请求,从而使得被攻击方资源耗尽(CPU满负荷或内存不足)的攻击方式。
HTTP请求包(浏览器信息)
我们先来看看Request包的结构, Request包分为3部分,第一部分叫Request line(请求行), 第二部分叫Request header(请求头),第三部分是body(主体)。header和body之间有个空行,请求包的例子所示:
GET /domains/example/ HTTP/1.1 //请求行: 请求方法 请求URI HTTP协议/协议版本
Host:www.iana.org //服务端的主机名
User-Agent:Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.4 (KHTML, like Gecko) Chrome/22.0.1229.94 Safari/537.4 //浏览器信息
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 //客户端能接收的mine
Accept-Encoding:gzip,deflate,sdch //是否支持流压缩
Accept-Charset:UTF-8,*;q=0.5 //客户端字符编码集
//空行,用于分割请求头和消息体
//消息体,请求资源参数,例如POST传递的参数HTTP协议定义了很多与服务器交互的请求方法,最基本的有4种,分别是GET,POST,PUT,DELETE。一个URL地址用于描述一个网络上的资源,而HTTP中的GET, POST, PUT, DELETE就对应着对这个资源的查,改,增,删4个操作。我们最常见的就是GET和POST了。GET一般用于获取/查询资源信息,而POST一般用于更新资源信息。
我们看看GET和POST的区别:
- 我们可以看到GET请求消息体为空,POST请求带有消息体。
- GET提交的数据会放在URL之后,以
?分割URL和传输数据,参数之间以&相连,如EditPosts.aspx?name=test1&id=123456。POST方法是把提交的数据放在HTTP包的body中。 - GET提交的数据大小有限制(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制。
- GET方式提交数据,会带来安全问题,比如一个登录页面,通过GET方式提交数据时,用户名和密码将出现在URL上,如果页面可以被缓存或者其他人可以访问这台机器,就可以从历史记录获得该用户的账号和密码。
HTTP响应包(服务器信息)
我们再来看看HTTP的response包,他的结构如下:
HTTP/1.1 200 OK //状态行
Server: nginx/1.0.8 //服务器使用的WEB软件名及版本
Date:Date: Tue, 30 Oct 2012 04:14:25 GMT //发送时间
Content-Type: text/html //服务器发送信息的类型
Transfer-Encoding: chunked //表示发送HTTP包是分段发的
Connection: keep-alive //保持连接状态
Content-Length: 90 //主体内容长度
//空行 用来分割消息头和主体
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"... //消息体Response包中的第一行叫做状态行,由HTTP协议版本号, 状态码, 状态消息 三部分组成。
状态码用来告诉HTTP客户端,HTTP服务器是否产生了预期的Response。HTTP/1.1协议中定义了5类状态码, 状态码由三位数字组成,第一个数字定义了响应的类别
- 1XX 提示信息 - 表示请求已被成功接收,继续处理
- 2XX 成功 - 表示请求已被成功接收,理解,接受
- 3XX 重定向 - 要完成请求必须进行更进一步的处理
- 4XX 客户端错误 - 请求有语法错误或请求无法实现
- 5XX 服务器端错误 - 服务器未能实现合法的请求
HTTP协议是无状态的和Connection: keep-alive的区别
无状态是指协议对于事务处理没有记忆能力,服务器不知道客户端是什么状态。从另一方面讲,打开一个服务器上的网页和你之前打开这个服务器上的网页之间没有任何联系。
HTTP是一个无状态的面向连接的协议,无状态不代表HTTP不能保持TCP连接,更不能代表HTTP使用的是UDP协议(面对无连接)。
从HTTP/1.1起,默认都开启了Keep-Alive保持连接特性,简单地说,当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,如果客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的TCP连接。
Keep-Alive不会永久保持连接,它有一个保持时间,可以在不同服务器软件(如Apache)中设置这个时间。
请求实例
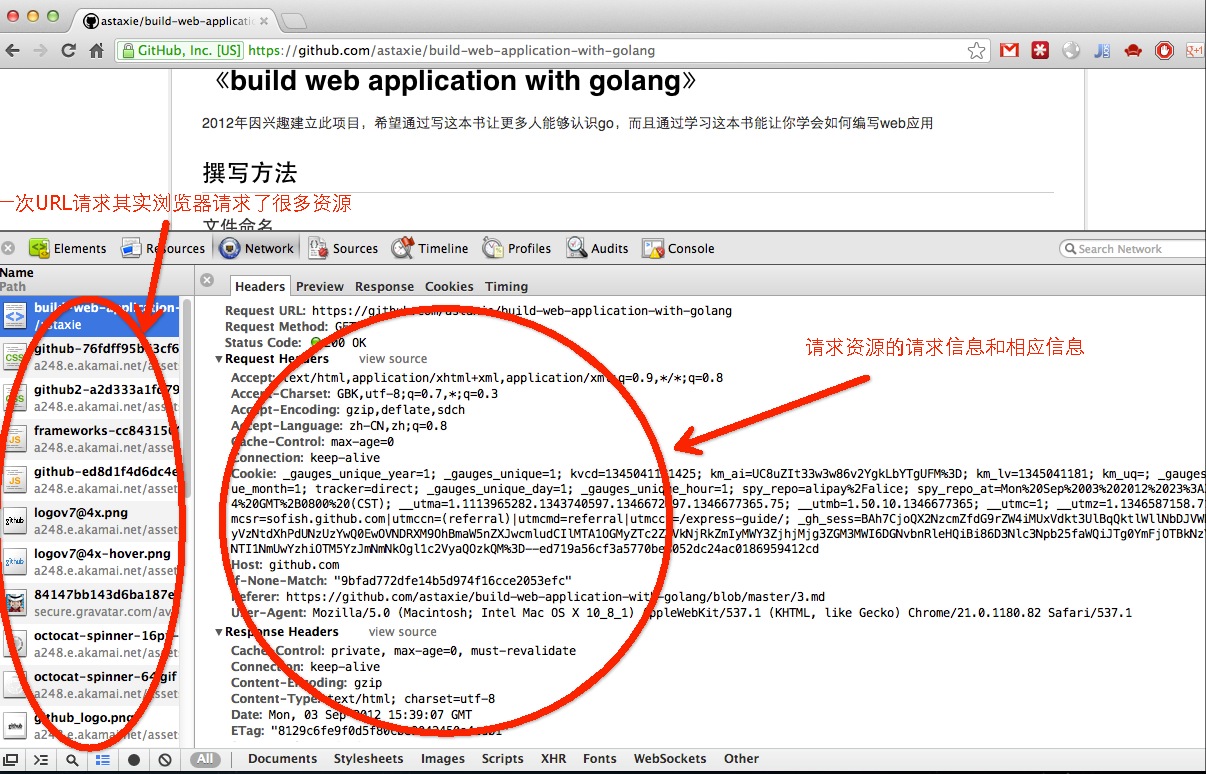
图3.7 一次请求的request和response
上面这张图我们可以了解到整个的通讯过程,同时细心的读者是否注意到了一点,一个URL请求但是左边栏里面为什么会有那么多的资源请求(这些都是静态文件,go对于静态文件有专门的处理方式)。
这个就是浏览器的一个功能,第一次请求url,服务器端返回的是html页面,然后浏览器开始渲染HTML:当解析到HTML DOM里面的图片连接,css脚本和js脚本的链接,浏览器就会自动发起一个请求静态资源的HTTP请求,获取相对应的静态资源,然后浏览器就会渲染出来,最终将所有资源整合、渲染,完整展现在我们面前的屏幕上。
网页优化方面有一项措施是减少HTTP请求次数,就是把尽量多的css和js资源合并在一起,目的是尽量减少网页请求静态资源的次数,提高网页加载速度,同时减缓服务器的压力。
3.2 Go搭建一个Web服务器
http包建立Web服务器
package main
import (
"fmt"
"net/http"
"strings"
"log"
)
func sayhelloName(w http.ResponseWriter, r *http.Request) {
r.ParseForm() //解析参数,默认是不会解析的
fmt.Println(r.Form) //这些信息是输出到服务器端的打印信息
fmt.Println("path", r.URL.Path)
fmt.Println("scheme", r.URL.Scheme)
fmt.Println(r.Form["url_long"])
for k, v := range r.Form {
fmt.Println("key:", k)
fmt.Println("val:", strings.Join(v, ""))
}
fmt.Fprintf(w, "Hello astaxie!") //这个写入到w的是输出到客户端的
}
func main() {
http.HandleFunc("/", sayhelloName) //设置访问的路由
err := http.ListenAndServe(":9090", nil) //设置监听的端口
if err != nil {
log.Fatal("ListenAndServe: ", err)
}
}浏览器输入:http://localhost:9090/?url_long=111&url_long=222
输出如下:

要编写一个Web服务器很简单,只要调用http包的两个函数就可以了。
如果你以前是PHP程序员,那你也许就会问,我们的nginx、apache服务器不需要吗?Go就是不需要这些,因为他直接就监听tcp端口了,做了nginx做的事情,然后sayhelloName这个其实就是我们写的逻辑函数了,跟php里面的控制层(controller)函数类似。
如果你以前是Python程序员,那么你一定听说过tornado,这个代码和他是不是很像,对,没错,Go就是拥有类似Python这样动态语言的特性,写Web应用很方便。
如果你以前是Ruby程序员,会发现和ROR的/script/server启动有点类似。
我们看到Go通过简单的几行代码就已经运行起来一个Web服务了,而且这个Web服务内部有支持高并发的特性,
3.3 Go如何使得Web工作
web工作方式的几个概念
以下均是服务器端的几个概念
Request:用户请求的信息,用来解析用户的请求信息,包括post、get、cookie、url等信息
Response:服务器需要反馈给客户端的信息
Conn:用户的每次请求链接
Handler:处理请求和生成返回信息的处理逻辑
分析http包运行机制
如下图所示,是Go实现Web服务的工作模式的流程图

- 创建Listen Socket, 监听指定的端口, 等待客户端请求到来。
- Listen Socket接受客户端的请求, 得到Client Socket, 接下来通过Client Socket与客户端通信。
- 处理客户端的请求, 首先从Client Socket读取HTTP请求的协议头, 如果是POST方法, 还可能要读取客户端提交的数据, 然后交给相应的handler处理请求, handler处理完毕准备好客户端需要的数据, 通过Client Socket写给客户端。
这整个的过程里面我们只要了解清楚下面三个问题,也就知道Go是如何让Web运行起来了
- 如何监听端口?
- 如何接收客户端请求?
- 如何分配handler?
前面小节的代码里面我们可以看到,Go是通过一个函数ListenAndServe来处理这些事情的,这个底层其实这样处理的:初始化一个server对象,然后调用了net.Listen("tcp", addr),也就是底层用TCP协议搭建了一个服务,然后监控我们设置的端口。
下面代码来自Go的http包的源码,通过下面的代码我们可以看到整个的http处理过程:
func (srv *Server) Serve(l net.Listener) error {
defer l.Close()
var tempDelay time.Duration // how long to sleep on accept failure
for {
rw, e := l.Accept()
if e != nil {
if ne, ok := e.(net.Error); ok && ne.Temporary() {
if tempDelay == 0 {
tempDelay = 5 * time.Millisecond
} else {
tempDelay *= 2
}
if max := 1 * time.Second; tempDelay > max {
tempDelay = max
}
log.Printf("http: Accept error: %v; retrying in %v", e, tempDelay)
time.Sleep(tempDelay)
continue
}
return e
}
tempDelay = 0
c, err := srv.newConn(rw)
if err != nil {
continue
}
go c.serve()
}
}监控之后如何接收客户端的请求呢?上面代码执行监控端口之后,调用了srv.Serve(net.Listener)函数,这个函数就是处理接收客户端的请求信息。这个函数里面起了一个for{},首先通过Listener接收请求,其次创建一个Conn,最后单独开了一个goroutine,把这个请求的数据当做参数扔给这个conn去服务:go c.serve()。这个就是高并发体现了,用户的每一次请求都是在一个新的goroutine去服务,相互不影响。
那么如何具体分配到相应的函数来处理请求呢?conn首先会解析request:c.readRequest(),然后获取相应的handler:handler := c.server.Handler,也就是我们刚才在调用函数ListenAndServe时候的第二个参数,我们前面例子传递的是nil,也就是为空,那么默认获取handler = DefaultServeMux,那么这个变量用来做什么的呢?对,这个变量就是一个路由器,它用来匹配url跳转到其相应的handle函数,那么这个我们有设置过吗?有,我们调用的代码里面第一句不是调用了http.HandleFunc("/", sayhelloName)嘛。这个作用就是注册了请求/的路由规则,当请求uri为”/“,路由就会转到函数sayhelloName,DefaultServeMux会调用ServeHTTP方法,这个方法内部其实就是调用sayhelloName本身,最后通过写入response的信息反馈到客户端。
详细的整个流程如下图所示:

3.4 Go的http包详解
Go的http有两个核心功能:Conn、ServeMux
Conn的goroutine
Go为了实现高并发和高性能, 使用了goroutines来处理Conn的读写事件, 这样每个请求都能保持独立,相互不会阻塞,可以高效的响应网络事件。这是Go高效的保证。
Go在等待客户端请求里面是这样写的:
c, err := srv.newConn(rw)
if err != nil {
continue
}
go c.serve()这里我们可以看到客户端的每次请求都会创建一个Conn,这个Conn里面保存了该次请求的信息,然后再传递到对应的handler,该handler中便可以读取到相应的header信息,这样保证了每个请求的独立性。
ServeMux的自定义
conn.server内部是调用了http包默认的路由器,通过路由器把本次请求的信息传递到了后端的处理函数。那么这个路由器是怎么实现的呢?
它的结构如下:
type ServeMux struct {
mu sync.RWMutex //锁,由于请求涉及到并发处理,因此这里需要一个锁机制
m map[string]muxEntry // 路由规则,一个string对应一个mux实体,这里的string就是注册的路由表达式
hosts bool // 是否在任意的规则中带有host信息
}下面看一下muxEntry
type muxEntry struct {
explicit bool // 是否精确匹配
h Handler // 这个路由表达式对应哪个handler
pattern string //匹配字符串
}接着看一下Handler的定义
type Handler interface {
ServeHTTP(ResponseWriter, *Request) // 路由实现器
}Handler是一个接口,但是前一小节中的sayhelloName函数并没有实现ServeHTTP这个接口,为什么能添加呢?原来在http包里面还定义了一个类型HandlerFunc,我们定义的函数sayhelloName就是这个HandlerFunc调用之后的结果,这个类型默认就实现了ServeHTTP这个接口,即我们调用了HandlerFunc(f),强制类型转换f成为HandlerFunc类型,这样f就拥有了ServeHTTP方法。
type HandlerFunc func(ResponseWriter, *Request)
// ServeHTTP calls f(w, r).
func (f HandlerFunc) ServeHTTP(w ResponseWriter, r *Request) {
f(w, r)
}路由器里面存储好了相应的路由规则之后,那么具体的请求又是怎么分发的呢?请看下面的代码,默认的路由器实现了ServeHTTP:
func (mux *ServeMux) ServeHTTP(w ResponseWriter, r *Request) {
if r.RequestURI == "*" {
w.Header().Set("Connection", "close")
w.WriteHeader(StatusBadRequest)
return
}
h, _ := mux.Handler(r)
h.ServeHTTP(w, r)
}如上所示路由器接收到请求之后,如果是*那么关闭链接,不然调用mux.Handler(r)返回对应设置路由的处理Handler,然后执行h.ServeHTTP(w, r)
也就是调用对应路由的handler的ServerHTTP接口,那么mux.Handler(r)怎么处理的呢?
func (mux *ServeMux) Handler(r *Request) (h Handler, pattern string) {
if r.Method != "CONNECT" {
if p := cleanPath(r.URL.Path); p != r.URL.Path {
_, pattern = mux.handler(r.Host, p)
return RedirectHandler(p, StatusMovedPermanently), pattern
}
}
return mux.handler(r.Host, r.URL.Path)
}
func (mux *ServeMux) handler(host, path string) (h Handler, pattern string) {
mux.mu.RLock()
defer mux.mu.RUnlock()
// Host-specific pattern takes precedence over generic ones
if mux.hosts {
h, pattern = mux.match(host + path)
}
if h == nil {
h, pattern = mux.match(path)
}
if h == nil {
h, pattern = NotFoundHandler(), ""
}
return
}原来他是根据用户请求的URL和路由器里面存储的map去匹配的,当匹配到之后返回存储的handler,调用这个handler的ServeHTTP接口就可以执行到相应的函数了。
通过上面这个介绍,我们了解了整个路由过程,Go其实支持外部实现的路由器 ListenAndServe的第二个参数就是用以配置外部路由器的,它是一个Handler接口,即外部路由器只要实现了Handler接口就可以,我们可以在自己实现的路由器的ServeHTTP里面实现自定义路由功能。
如下代码所示,我们自己实现了一个简易的路由器
package main
import (
"fmt"
"net/http"
)
type MyMux struct {
}
func (p *MyMux) ServeHTTP(w http.ResponseWriter, r *http.Request) {
if r.URL.Path == "/" {
sayhelloName(w, r)
return
}
http.NotFound(w, r)
return
}
func sayhelloName(w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "Hello myroute!")
}
func main() {
mux := &MyMux{}
http.ListenAndServe(":9090", mux)
}Go代码的执行流程
通过对http包的分析之后,现在让我们来梳理一下整个的代码执行过程。
首先调用Http.HandleFunc
按顺序做了几件事:
1 调用了DefaultServeMux的HandleFunc
2 调用了DefaultServeMux的Handle
3 往DefaultServeMux的map[string]muxEntry中增加对应的handler和路由规则
其次调用http.ListenAndServe(“:9090”, nil)
按顺序做了几件事情:
1 实例化Server
2 调用Server的ListenAndServe()
3 调用net.Listen(“tcp”, addr)监听端口
4 启动一个for循环,在循环体中Accept请求
5 对每个请求实例化一个Conn,并且开启一个goroutine为这个请求进行服务go c.serve()
6 读取每个请求的内容w, err := c.readRequest()
7 判断handler是否为空,如果没有设置handler(这个例子就没有设置handler),handler就设置为DefaultServeMux
8 调用handler的ServeHttp
9 在这个例子中,下面就进入到DefaultServeMux.ServeHttp
10 根据request选择handler,并且进入到这个handler的ServeHTTP
mux.handler(r).ServeHTTP(w, r)11 选择handler:
A 判断是否有路由能满足这个request(循环遍历ServerMux的muxEntry)
B 如果有路由满足,调用这个路由handler的ServeHttp
C 如果没有路由满足,调用NotFoundHandler的ServeHttp
4 表单
在Request里面的有专门的form处理,可以很方便的整合到Web开发里面来,4.1小节里面将讲解Go如何处理表单的输入。由于不能信任任何用户的输入,所以我们需要对这些输入进行有效性验证,4.2小节将就如何进行一些普通的验证进行详细的演示。
HTTP协议是一种无状态的协议,那么如何才能辨别是否是同一个用户呢?同时又如何保证一个表单不出现多次递交的情况呢?4.3和4.4小节里面将对cookie(cookie是存储在客户端的信息,能够每次通过header和服务器进行交互的数据)等进行详细讲解。
表单还有一个很大的功能就是能够上传文件,那么Go是如何处理文件上传的呢?针对大文件上传我们如何有效的处理呢?4.5小节我们将一起学习Go处理文件上传的知识。

4.1 处理表单的输入
package main
import (
"fmt"
"html/template"
"log"
"net/http"
"strings"
)
func sayhelloName(w http.ResponseWriter, r *http.Request) {
r.ParseForm() //解析url传递的参数,对于POST则解析响应包的主体(request body)
//注意:如果没有调用ParseForm方法,下面无法获取表单的数据
fmt.Println(r.Form) //这些信息是输出到服务器端的打印信息
fmt.Println("path", r.URL.Path)
fmt.Println("scheme", r.URL.Scheme)
fmt.Println(r.Form["url_long"])
for k, v := range r.Form {
fmt.Println("key:", k)
fmt.Println("val:", strings.Join(v, ""))
}
fmt.Fprintf(w, "Hello astaxie!") //这个写入到w的是输出到客户端的
}
func login(w http.ResponseWriter, r *http.Request) {
fmt.Println("method:", r.Method) //获取请求的方法
if r.Method == "GET" {
t, _ := template.ParseFiles("login.html")
t.Execute(w, nil)
} else {
//请求的是登陆数据,那么执行登陆的逻辑判断
fmt.Println("username:", r.Form["username"])
fmt.Println("password:", r.Form["password"])
}
}
func main() {
http.HandleFunc("/", sayhelloName) //设置访问的路由
http.HandleFunc("/login", login) //设置访问的路由
err := http.ListenAndServe(":9090", nil) //设置监听的端口
if err != nil {
log.Fatal("ListenAndServe: ", err)
}
}<html>
<head>
<title></title>
</head>
<body>
<form action="/login" method="post">
用户名:<input type="text" name="username">
密码:<input type="password" name="password">
<input type="submit" value="登陆">
</form>
</body>
</html>我们输入用户名和密码之后发现在服务器端是不会打印出来任何输出的,为什么呢?默认情况下,Handler里面是不会自动解析form的,必须显式的调用r.ParseForm()后,你才能对这个表单数据进行操作。我们修改一下代码,在fmt.Println("username:", r.Form["username"])之前加一行r.ParseForm(),重新编译,再次测试输入递交,现在是不是在服务器端有输出你的输入的用户名和密码了。
r.Form里面包含了所有请求的参数,比如URL中query-string、POST的数据、PUT的数据,所有当你在URL的query-string字段和POST冲突时,会保存成一个slice,里面存储了多个值,Go官方文档中说在接下来的版本里面将会把POST、GET这些数据分离开来。
…….
request.Form是一个url.Values类型,里面存储的是对应的类似key=value的信息,下面展示了可以对form数据进行的一些操作:
v := url.Values{}
v.Set("name", "Ava")
v.Add("friend", "Jess")
v.Add("friend", "Sarah")
v.Add("friend", "Zoe")
// v.Encode() == "name=Ava&friend=Jess&friend=Sarah&friend=Zoe"
fmt.Println(v.Get("name"))
fmt.Println(v.Get("friend"))
fmt.Println(v["friend"])Tips: Request本身也提供了FormValue()函数来获取用户提交的参数。如r.Form[“username”]也可写成r.FormValue(“username”)。调用r.FormValue时会自动调用r.ParseForm,所以不必提前调用。r.FormValue只会返回同名参数中的第一个,若参数不存在则返回空字符串。
4.2 验证表单的输入
我们平常编写Web应用主要有两方面的数据验证,一个是在页面端的js验证(目前在这方面有很多的插件库,比如ValidationJS插件),一个是在服务器端的验证,我们这小节讲解的是如何在服务器端验证。
必填字段
if len(r.Form["username"][0])==0{
//为空的处理
}r.Form对不同类型的表单元素的留空有不同的处理, 对于空文本框、空文本区域以及文件上传,元素的值为空值,而如果是未选中的复选框和单选按钮,则根本不会在r.Form中产生相应条目,如果我们用上面例子中的方式去获取数据时程序就会报错。所以我们需要通过r.Form.Get()来获取值,因为如果字段不存在,通过该方式获取的是空值。但是通过r.Form.Get()只能获取单个的值,如果是map的值,必须通过上面的方式来获取。
数字
如果我们是判断正整数,那么我们先转化成int类型,然后进行处理
getint,err:=strconv.Atoi(r.Form.Get("age"))
if err!=nil{
//数字转化出错了,那么可能就不是数字
}
//接下来就可以判断这个数字的大小范围了
if getint >100 {
//太大了
}还有一种方式就是正则匹配的方式
if m, _ := regexp.MatchString("^[0-9]+$", r.Form.Get("age")); !m {
return false
}中文
对于中文我们目前有两种方式来验证,可以使用 unicode 包提供的 func Is(rangeTab *RangeTable, r rune) bool 来验证,也可以使用正则方式来验证,这里使用最简单的正则方式,如下代码所示
if m, _ := regexp.MatchString("^\\p{Han}+$", r.Form.Get("realname")); !m {
return false
}电子邮件地址
你想知道用户输入的一个Email地址是否正确,通过如下这个方式可以验证:
if m, _ := regexp.MatchString(`^([\w\.\_]{2,10})@(\w{1,}).([a-z]{2,4})$`, r.Form.Get("email")); !m {
fmt.Println("no")
}else{
fmt.Println("yes")
}手机号码
你想要判断用户输入的手机号码是否正确,通过正则也可以验证:
if m, _ := regexp.MatchString(`^(1[3|4|5|8][0-9]\d{4,8})$`, r.Form.Get("mobile")); !m {
return false
}单选按钮
如果我们想要判断radio按钮是否有一个被选中了,我们页面的输出可能就是一个男、女性别的选择,但是也可能一个15岁大的无聊小孩,一手拿着http协议的书,另一只手通过telnet客户端向你的程序在发送请求呢,你设定的性别男值是1,女是2,他给你发送一个3,你的程序会出现异常吗?因此我们也需要像下拉菜单的判断方式类似,判断我们获取的值是我们预设的值,而不是额外的值。
<input type="radio" name="gender" value="1">男
<input type="radio" name="gender" value="2">女那我们也可以类似下拉菜单的做法一样
slice:=[]int{1,2}
for _, v := range slice {
if v == r.Form.Get("gender") {
return true
}
}
return false复选框同理。
日期和时间
你想确定用户填写的日期或时间是否有效。例如 ,用户在日程表中安排8月份的第45天开会,或者提供未来的某个时间作为生日。
Go里面提供了一个time的处理包,我们可以把用户的输入年月日转化成相应的时间,然后进行逻辑判断
t := time.Date(2009, time.November, 10, 23, 0, 0, 0, time.UTC)
fmt.Printf("Go launched at %s\n", t.Local())获取time之后我们就可以进行很多时间函数的操作。具体的判断就根据自己的需求调整。
身份证号码
如果我们想验证表单输入的是否是身份证,通过正则也可以方便的验证,但是身份证有15位和18位,我们两个都需要验证
//验证15位身份证,15位的是全部数字
if m, _ := regexp.MatchString(`^(\d{15})$`, r.Form.Get("usercard")); !m {
return false
}
//验证18位身份证,18位前17位为数字,最后一位是校验位,可能为数字或字符X。
if m, _ := regexp.MatchString(`^(\d{17})([0-9]|X)$`, r.Form.Get("usercard")); !m {
return false
}4.3 预防跨站脚本
cross-site-scripting (XSS)
攻击者通常会在有漏洞的程序中插入JavaScript、VBScript、 ActiveX或Flash以欺骗用户。一旦得手,他们可以盗取用户帐户信息,修改用户设置,盗取/污染cookie和植入恶意广告等。
对XSS最佳的防护应该结合以下两种方法:一是验证所有输入数据,有效检测攻击(这个我们前面小节已经有过介绍);另一个是对所有输出数据进行适当的处理,以防止任何已成功注入的脚本在浏览器端运行。
那么Go里面是怎么做这个有效防护的呢?Go的html/template里面带有下面几个函数可以帮你转义
- func HTMLEscape(w io.Writer, b []byte) //把b进行转义之后写到w
- func HTMLEscapeString(s string) string //转义s之后返回结果字符串
- func HTMLEscaper(args …interface{}) string //支持多个参数一起转义,返回结果字符串
我们看4.1小节的例子
fmt.Println("username:", template.HTMLEscapeString(r.Form.Get("username"))) //输出到服务器端
fmt.Println("password:", template.HTMLEscapeString(r.Form.Get("password")))
template.HTMLEscape(w, []byte(r.Form.Get("username"))) //输出到客户端如果我们输入的username是<script>alert()</script>,那么我们可以在浏览器上面看到输出如下所示:
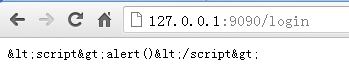
图4.3 Javascript过滤之后的输出
Go的html/template包默认帮你过滤了html标签,但是有时候你只想要输出这个<script>alert()</script>看起来正常的信息,该怎么处理?请使用text/template。请看下面的例子:
import "text/template"
...
t, err := template.New("foo").Parse(`{{define "T"}}Hello, {{.}}!{{end}}`)
err = t.ExecuteTemplate(out, "T", "<script>alert('you have been pwned')</script>")输出
Hello, <script>alert('you have been pwned')</script>!或者使用template.HTML类型
import "html/template"
...
t, err := template.New("foo").Parse(`{{define "T"}}Hello, {{.}}!{{end}}`)
err = t.ExecuteTemplate(out, "T", template.HTML("<script>alert('you have been pwned')</script>"))输出
Hello, <script>alert('you have been pwned')</script>!转换成template.HTML后,变量的内容也不会被转义
4.4 防止多次递交表单
解决方案是在表单中添加一个带有唯一值的隐藏字段。在验证表单时,先检查带有该惟一值的表单是否已经递交过了。如果是,拒绝再次递交;如果不是,则处理表单进行逻辑处理。另外,如果是采用了Ajax模式递交表单的话,当表单递交后,通过javascript来禁用表单的递交按钮。
用户名:<input type="text" name="username">
密码:<input type="password" name="password">
<input type="hidden" name="token" value="{{.}}">
<input type="submit" value="登陆">隐藏字段token,这个值我们通过MD5(时间戳)来获取惟一值,然后我们把这个值存储到服务器端(session来控制,我们将在第六章讲解如何保存),以方便表单提交时比对判定。
func login(w http.ResponseWriter, r *http.Request) {
fmt.Println("method:", r.Method) //获取请求的方法
if r.Method == "GET" {
crutime := time.Now().Unix()
h := md5.New()
io.WriteString(h, strconv.FormatInt(crutime, 10))
token := fmt.Sprintf("%x", h.Sum(nil))
t, _ := template.ParseFiles("login.gtpl")
t.Execute(w, token)
} else {
//请求的是登陆数据,那么执行登陆的逻辑判断
r.ParseForm()
token := r.Form.Get("token")
if token != "" {
//验证token的合法性
} else {
//不存在token报错
}
fmt.Println("username length:", len(r.Form["username"][0]))
fmt.Println("username:", template.HTMLEscapeString(r.Form.Get("username"))) //输出到服务器端
fmt.Println("password:", template.HTMLEscapeString(r.Form.Get("password")))
template.HTMLEscape(w, []byte(r.Form.Get("username"))) //输出到客户端
}
}上面的代码输出到页面的源码如下:
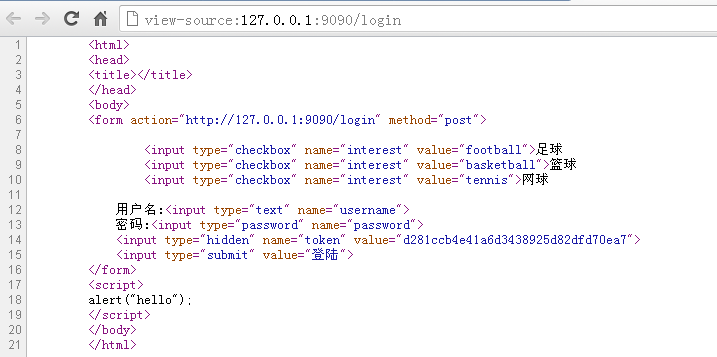
图4.4 增加token之后在客户端输出的源码信息
每次刷新这个token的value都会变化。这样就保证了每次显示Form表单的时候都是唯一的,用户递交的表单保持了唯一性
我们的解决方案可以防止非恶意的攻击,并能使恶意用户暂时不知所措,然后,它却不能排除所有的欺骗性的动机,对此类情况还需要更复杂的工作
4.5 处理文件上传
要使表单能够上传文件,首先第一步就是要添加form的enctype属性,enctype属性有如下三种情况:
application/x-www-form-urlencoded 表示在发送前编码所有字符(默认)
multipart/form-data 不对字符编码。在使用包含文件上传控件的表单时,必须使用该值。
text/plain 空格转换为 "+" 加号,但不对特殊字符编码。所以,表单的html代码应该类似于:
<html>
<head>
<title>上传文件</title>
</head>
<body>
<form enctype="multipart/form-data" action="http://127.0.0.1:9090/upload" method="post">
<input type="file" name="uploadfile" />
<input type="hidden" name="token" value="{{.}}"/>
<input type="submit" value="upload" />
</form>
</body>
</html>在服务器端,我们增加一个handlerFunc:
http.HandleFunc("/upload", upload)
// 处理/upload 逻辑
func upload(w http.ResponseWriter, r *http.Request) {
fmt.Println("method:", r.Method) //获取请求的方法
if r.Method == "GET" {
crutime := time.Now().Unix()
h := md5.New()
io.WriteString(h, strconv.FormatInt(crutime, 10))
token := fmt.Sprintf("%x", h.Sum(nil))
t, _ := template.ParseFiles("upload.gtpl")
t.Execute(w, token)
} else {
r.ParseMultipartForm(32 << 20)
file, handler, err := r.FormFile("uploadfile")
if err != nil {
fmt.Println(err)
return
}
defer file.Close()
fmt.Fprintf(w, "%v", handler.Header)
f, err := os.OpenFile("./test/"+handler.Filename, os.O_WRONLY|os.O_CREATE, 0666)
if err != nil {
fmt.Println(err)
return
}
defer f.Close()
io.Copy(f, file)
}
}通过上面的代码可以看到,处理文件上传我们需要调用r.ParseMultipartForm,里面的参数表示maxMemory,调用ParseMultipartForm之后,上传的文件存储在maxMemory大小的内存里面,如果文件大小超过了maxMemory,那么剩下的部分将存储在系统的临时文件中。我们可以通过r.FormFile获取上面的文件句柄,然后实例中使用了io.Copy来存储文件。
获取其他非文件字段信息的时候就不需要调用
r.ParseForm,因为在需要的时候Go自动会去调用。而且ParseMultipartForm调用一次之后,后面再次调用不会再有效果。
通过上面的实例我们可以看到我们上传文件主要三步处理:
- 表单中增加enctype=”multipart/form-data”
- 服务端调用
r.ParseMultipartForm,把上传的文件存储在内存和临时文件中 - 使用
r.FormFile获取文件句柄,然后对文件进行存储等处理。
文件handler是multipart.FileHeader,里面存储了如下结构信息
type FileHeader struct {
Filename string
Header textproto.MIMEHeader
// contains filtered or unexported fields
}通过上面的实例代码打印出来上传文件的信息如下

图4.5 打印文件上传后服务器端接受的信息
客户端上传文件
我们上面的例子演示了如何通过表单上传文件,然后在服务器端处理文件,其实Go支持模拟客户端表单功能支持文件上传,详细用法请看如下示例:
package main
import (
"bytes"
"fmt"
"io"
"io/ioutil"
"mime/multipart"
"net/http"
"os"
)
func postFile(filename string, targetUrl string) error {
bodyBuf := &bytes.Buffer{}
bodyWriter := multipart.NewWriter(bodyBuf)
//关键的一步操作
fileWriter, err := bodyWriter.CreateFormFile("uploadfile", filename)
if err != nil {
fmt.Println("error writing to buffer")
return err
}
//打开文件句柄操作
fh, err := os.Open(filename)
if err != nil {
fmt.Println("error opening file")
return err
}
defer fh.Close()
//iocopy
_, err = io.Copy(fileWriter, fh)
if err != nil {
return err
}
contentType := bodyWriter.FormDataContentType()
bodyWriter.Close()
resp, err := http.Post(targetUrl, contentType, bodyBuf)
if err != nil {
return err
}
defer resp.Body.Close()
resp_body, err := ioutil.ReadAll(resp.Body)
if err != nil {
return err
}
fmt.Println(resp.Status)
fmt.Println(string(resp_body))
return nil
}
// sample usage
func main() {
target_url := "http://localhost:9090/upload"
filename := "./astaxie.pdf"
postFile(filename, target_url)
}上面的例子详细展示了客户端如何向服务器上传一个文件的例子,客户端通过multipart.Write把文件的文本流写入一个缓存中,然后调用http的Post方法把缓存传到服务器。
如果你还有其他普通字段例如username之类的需要同时写入,那么可以调用multipart的WriteField方法写很多其他类似的字段。
5 访问数据库
Go没有内置的驱动支持任何的数据库,但是Go定义了database/sql接口,用户可以基于驱动接口开发相应数据库的驱动,5.1小节里面介绍Go设计的一些驱动,介绍Go是如何设计数据库驱动接口的。5.2至5.4小节介绍目前使用的比较多的一些关系型数据驱动以及如何使用,5.5小节介绍我自己开发一个ORM库,基于database/sql标准接口开发的,可以兼容几乎所有支持database/sql的数据库驱动,可以方便的使用Go style来进行数据库操作。
目前NOSQL已经成为Web开发的一个潮流,很多应用采用了NOSQL作为数据库,而不是以前的缓存,5.6小节将介绍MongoDB和Redis两种NOSQL数据库。

5.1 database/sql接口
开发者可以根据定义的接口来开发相应的数据库驱动,这样做有一个好处,只要是按照标准接口开发的代码, 以后需要迁移数据库时,不需要任何修改。
SQL.Register
这个存在于database/sql的函数是用来注册数据库驱动的,当第三方开发者开发数据库驱动时,都会实现init函数,在init里面会调用这个Register(name string, driver driver.Driver)完成本驱动的注册。
我们来看一下mymysql、sqlite3的驱动里面都是怎么调用的:
//https://github.com/mattn/go-sqlite3驱动
func init() {
sql.Register("sqlite3", &SQLiteDriver{})
}
//https://github.com/mikespook/mymysql驱动
// Driver automatically registered in database/sql
var d = Driver{proto: "tcp", raddr: "127.0.0.1:3306"}
func init() {
Register("SET NAMES utf8")
sql.Register("mymysql", &d)
}我们看到第三方数据库驱动都是通过调用这个函数来注册自己的数据库驱动名称以及相应的driver实现。在database/sql内部通过一个map来存储用户定义的相应驱动。
var drivers = make(map[string]driver.Driver)
drivers[name] = driver因此通过database/sql的注册函数可以同时注册多个数据库驱动,只要不重复。
在我们使用database/sql接口和第三方库的时候经常看到如下:
import ( "database/sql" _ "github.com/mattn/go-sqlite3" )新手都会被这个
_所迷惑,其实这个就是Go设计的巧妙之处,我们在变量赋值的时候经常看到这个符号,它是用来忽略变量赋值的占位符,那么包引入用到这个符号也是相似的作用,这儿使用_的意思是引入后面的包名而不直接使用这个包中定义的函数,变量等资源。包在引入的时候会自动调用包的init函数以完成对包的初始化。因此,我们引入上面的数据库驱动包之后会自动去调用init函数,然后在init函数里面注册这个数据库驱动,这样我们就可以在接下来的代码中直接使用这个数据库驱动了。
driver.Driver
Driver是一个数据库驱动的接口,他定义了一个method: Open(name string),这个方法返回一个数据库的Conn接口。
type Driver interface {
Open(name string) (Conn, error)
}返回的Conn只能用来进行一次goroutine的操作,也就是说不能把这个Conn应用于Go的多个goroutine里面。如下代码会出现错误
...
go goroutineA (Conn) //执行查询操作
go goroutineB (Conn) //执行插入操作
...上面这样的代码可能会使Go不知道某个操作究竟是由哪个goroutine发起的,从而导致数据混乱,比如可能会把goroutineA里面执行的查询操作的结果返回给goroutineB从而使B错误地把此结果当成自己执行的插入数据。
第三方驱动都会定义这个函数,它会解析name参数来获取相关数据库的连接信息,解析完成后,它将使用此信息来初始化一个Conn并返回它。
driver.Conn
Conn是一个数据库连接的接口定义,他定义了一系列方法,这个Conn只能应用在一个goroutine里面,不能使用在多个goroutine里面,
type Conn interface {
Prepare(query string) (Stmt, error)
Close() error
Begin() (Tx, error)
}Prepare函数返回与当前连接相关的执行Sql语句的准备状态,可以进行查询、删除等操作。
Close函数关闭当前的连接,执行释放连接拥有的资源等清理工作。因为驱动实现了database/sql里面建议的conn pool,所以你不用再去实现缓存conn之类的,这样会容易引起问题。
Begin函数返回一个代表事务处理的Tx,通过它你可以进行查询,更新等操作,或者对事务进行回滚、递交。
driver.Stmt
Stmt是一种准备好的状态,和Conn相关联,而且只能应用于一个goroutine中,不能应用于多个goroutine。
type Stmt interface {
Close() error
NumInput() int
Exec(args []Value) (Result, error)
Query(args []Value) (Rows, error)
}Close函数关闭当前的链接状态,但是如果当前正在执行query,query还是有效返回rows数据。
NumInput函数返回当前预留参数的个数,当返回>=0时数据库驱动就会智能检查调用者的参数。当数据库驱动包不知道预留参数的时候,返回-1。
Exec函数执行Prepare准备好的sql,传入参数执行update/insert等操作,返回Result数据
Query函数执行Prepare准备好的sql,传入需要的参数执行select操作,返回Rows结果集
Driver.Tx
事务处理一般就两个过程,递交或者回滚。数据库驱动里面也只需要实现这两个函数就可以
type Tx interface {
Commit() error
Rollback() error
}这两个函数一个用来递交一个事务,一个用来回滚事务。
driver.Execer
这是一个Conn可选择实现的接口
type Execer interface {
Exec(query string, args []Value) (Result, error)
}如果这个接口没有定义,那么在调用DB.Exec,就会首先调用Prepare返回Stmt,然后执行Stmt的Exec,然后关闭Stmt。
driver.Result
这个是执行Update/Insert等操作返回的结果接口定义
type Result interface {
LastInsertId() (int64, error)
RowsAffected() (int64, error)
}LastInsertId函数返回由数据库执行插入操作得到的自增ID号。
RowsAffected函数返回query操作影响的数据条目数。
driver.Rows
Rows是执行查询返回的结果集接口定义
type Rows interface {
Columns() []string
Close() error
Next(dest []Value) error
}Columns函数返回查询数据库表的字段信息,这个返回的slice和sql查询的字段一一对应,而不是返回整个表的所有字段。
Close函数用来关闭Rows迭代器。
Next函数用来返回下一条数据,把数据赋值给dest。dest里面的元素必须是driver.Value的值除了string,返回的数据里面所有的string都必须要转换成[]byte。如果最后没数据了,Next函数最后返回io.EOF。
……..
5.2 使用MySQL数据库
目前Internet上流行的网站构架方式是LAMP,其中的M即MySQL,
MySQL驱动
通过上面的代码我们可以看出,Go操作Mysql数据库是很方便的。
关键的几个函数我解释一下:
sql.Open()函数用来打开一个注册过的数据库驱动,go-sql-driver中注册了mysql这个数据库驱动,第二个参数是DSN(Data Source Name),它是go-sql-driver定义的一些数据库链接和配置信息。它支持如下格式:
[email protected](/path/to/socket)/dbname?charset=utf8
user:[email protected](localhost:5555)/dbname?charset=utf8
user:[email protected]/dbname
user:[email protected]([de:ad:be:ef::ca:fe]:80)/dbnamedb.Prepare()函数用来返回准备要执行的sql操作,然后返回准备完毕的执行状态。
db.Query()函数用来直接执行Sql返回Rows结果。
stmt.Exec()函数用来执行stmt准备好的SQL语句
我们可以看到我们传入的参数都是=?对应的数据,这样做的方式可以一定程度上防止SQL注入。
5.3 使用SQLite数据库
SQLite 是一个开源的嵌入式关系数据库,实现自包容、零配置、支持事务的SQL数据库引擎。其特点是高度便携、使用方便、结构紧凑、高效、可靠。 与其他数据库管理系统不同,SQLite 的安装和运行非常简单,在大多数情况下,只要确保SQLite的二进制文件存在即可开始创建、连接和使用数据库。如果您正在寻找一个嵌入式数据库项目或解决方案,SQLite是绝对值得考虑。SQLite可以是说开源的Access
5.4 使用PostgreSQL数据库
PostgreSQL 是一个自由的对象-关系数据库服务器(数据库管理系统),它在灵活的 BSD-风格许可证下发行。它提供了相对其他开放源代码数据库系统(比如 MySQL 和 Firebird),和对专有系统比如 Oracle、Sybase、IBM 的 DB2 和 Microsoft SQL Server的一种选择。
PostgreSQL和MySQL比较,它更加庞大一点,因为它是用来替代Oracle而设计的。所以在企业应用中采用PostgreSQL是一个明智的选择。
MySQL被Oracle收购之后正在逐步的封闭(自MySQL 5.5.31以后的所有版本将不再遵循GPL协议),鉴于此,将来我们也许会选择PostgreSQL而不是MySQL作为项目的后端数据库。
5.5 使用beedb库进行ORM开发
beedb是我开发的一个Go进行ORM操作的库,它采用了Go style方式对数据库进行操作,实现了struct到数据表记录的映射。beedb是一个十分轻量级的Go ORM框架,开发这个库的本意降低复杂的ORM学习曲线,尽可能在ORM的运行效率和功能之间寻求一个平衡,beedb是目前开源的Go ORM框架中实现比较完整的一个库,而且运行效率相当不错,功能也基本能满足需求。但是目前还不支持关系关联,这个是接下来版本升级的重点。
5.6 NOSQL数据库操作
NoSQL(Not Only SQL),指的是非关系型的数据库。随着Web2.0的兴起,传统的关系数据库在应付Web2.0网站,特别是超大规模和高并发的SNS类型的Web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。
而Go语言作为21世纪的C语言,对NOSQL的支持也是很好,目前流行的NOSQL主要有redis、mongoDB、Cassandra和Membase等。这些数据库都有高性能、高并发读写等特点,目前已经广泛应用于各种应用中。我接下来主要讲解一下redis和mongoDB的操作。
redis
redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)和zset(有序集合)。
目前应用redis最广泛的应该是新浪微博平台,其次还有Facebook收购的图片社交网站instagram。
package main
import (
"github.com/astaxie/goredis"
"fmt"
)
func main() {
var client goredis.Client
// 设置端口为redis默认端口
client.Addr = "127.0.0.1:6379"
//字符串操作
client.Set("a", []byte("hello"))
val, _ := client.Get("a")
fmt.Println(string(val))
client.Del("a")
//list操作
vals := []string{"a", "b", "c", "d", "e"}
for _, v := range vals {
client.Rpush("l", []byte(v))
}
dbvals,_ := client.Lrange("l", 0, 4)
for i, v := range dbvals {
println(i,":",string(v))
}
client.Del("l")
}我们可以看到操作redis非常的方便,而且我实际项目中应用下来性能也很高。client的命令和redis的命令基本保持一致。所以和原生态操作redis非常类似。
mongoDB
MongoDB是一个高性能,开源,无模式的文档型数据库,是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。他支持的数据结构非常松散,采用的是类似json的bjson格式来存储数据,因此可以存储比较复杂的数据类型。Mongo最大的特点是他支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
下图展示了mysql和mongoDB之间的对应关系,我们可以看出来非常的方便,但是mongoDB的性能非常好。

package main
import (
"fmt"
"labix.org/v2/mgo"
"labix.org/v2/mgo/bson"
)
type Person struct {
Name string
Phone string
}
func main() {
session, err := mgo.Dial("server1.example.com,server2.example.com")
if err != nil {
panic(err)
}
defer session.Close()
session.SetMode(mgo.Monotonic, true)
c := session.DB("test").C("people")
err = c.Insert(&Person{"Ale", "+55 53 8116 9639"},
&Person{"Cla", "+55 53 8402 8510"})
if err != nil {
panic(err)
}
result := Person{}
err = c.Find(bson.M{"name": "Ale"}).One(&result)
if err != nil {
panic(err)
}
fmt.Println("Phone:", result.Phone)
}我们可以看出来mgo的操作方式和beedb的操作方式几乎类似,都是基于struct的操作方式,这个就是Go Style。
6 session和数据存储
Web开发中一个很重要的议题就是如何做好用户的整个浏览过程的控制,因为HTTP协议是无状态的,所以用户的每一次请求都是无状态的,我们不知道在整个Web操作过程中哪些连接与该用户有关,我们应该如何来解决这个问题呢?Web里面经典的解决方案是cookie和session,cookie机制是一种客户端机制,把用户数据保存在客户端,而session机制是一种服务器端的机制,服务器使用一种类似于散列表的结构来保存信息,每一个网站访客都会被分配给一个唯一的标志符,即sessionID,它的存放形式无非两种:要么经过url传递,要么保存在客户端的cookies里.当然,你也可以将Session保存到数据库里,这样会更安全,但效率方面会有所下降。
6.1小节里面讲介绍session机制和cookie机制的关系和区别,6.2讲解Go语言如何来实现session,里面讲实现一个简易的session管理器,6.3小节讲解如何防止session被劫持的情况,如何有效的保护session。我们知道session其实可以存储在任何地方,6.3小节里面实现的session是存储在内存中的,但是如果我们的应用进一步扩展了,要实现应用的session共享,那么我们可以把session存储在数据库中(memcache或者redis),6.4小节将详细的讲解如何实现这些功能。
6.1 Session&&Cookie
当用户来到微博登陆页面,输入用户名和密码之后点击“登录”后浏览器将认证信息POST给远端的服务器,服务器执行验证逻辑,如果验证通过,则浏览器会跳转到登录用户的微博首页,在登录成功后,服务器如何验证我们对其他受限制页面的访问呢?因为HTTP协议是无状态的,所以很显然服务器不可能知道我们已经在上一次的HTTP请求中通过了验证。当然,最简单的解决方案就是所有的请求里面都带上用户名和密码,这样虽然可行,但大大加重了服务器的负担(对于每个request都需要到数据库验证),也大大降低了用户体验(每个页面都需要重新输入用户名密码,每个页面都带有登录表单)。既然直接在请求中带上用户名与密码不可行,那么就只有在服务器或客户端保存一些类似的可以代表身份的信息了,所以就有了cookie与session。
cookie,简而言之就是在本地计算机保存一些用户操作的历史信息(当然包括登录信息),并在用户再次访问该站点时浏览器通过HTTP协议将本地cookie内容发送给服务器,从而完成验证,或继续上一步操作。
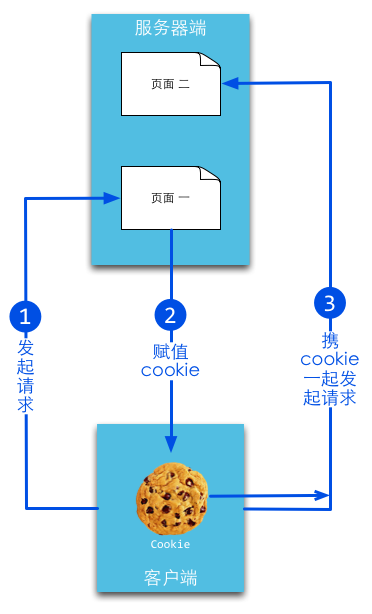
session,简而言之就是在服务器上保存用户操作的历史信息。服务器使用session id来标识session,session id由服务器负责产生,保证随机性与唯一性,相当于一个随机密钥,避免在握手或传输中暴露用户真实密码。但该方式下,仍然需要将发送请求的客户端与session进行对应,所以可以借助cookie机制来获取客户端的标识(即session id),也可以通过GET方式将id提交给服务器。
Cookie
Cookie是由浏览器维持的,存储在客户端的一小段文本信息,伴随着用户请求和页面在Web服务器和浏览器之间传递。用户每次访问站点时,Web应用程序都可以读取cookie包含的信息。浏览器设置里面有cookie隐私数据选项,打开它,可以看到很多已访问网站的cookies,
cookie是有时间限制的,根据生命期不同分成两种:会话cookie和持久cookie;
如果不设置过期时间,则表示这个cookie生命周期为从创建到浏览器关闭止,只要关闭浏览器窗口,cookie就消失了。这种生命期为浏览会话期的cookie被称为会话cookie。会话cookie一般不保存在硬盘上而是保存在内存里。
如果设置了过期时间(setMaxAge(606024)),浏览器就会把cookie保存到硬盘上,关闭后再次打开浏览器,这些cookie依然有效直到超过设定的过期时间。存储在硬盘上的cookie可以在不同的浏览器进程间共享,比如两个IE窗口。而对于保存在内存的cookie,不同的浏览器有不同的处理方式
Go语言中通过net/http包中的SetCookie来设置:
http.SetCookie(w ResponseWriter, cookie *Cookie)w表示需要写入的response,cookie是一个struct,让我们来看一下cookie对象是怎么样的
type Cookie struct {
Name string
Value string
Path string
Domain string
Expires time.Time
RawExpires string
// MaxAge=0 means no 'Max-Age' attribute specified.
// MaxAge<0 means delete cookie now, equivalently 'Max-Age: 0'
// MaxAge>0 means Max-Age attribute present and given in seconds
MaxAge int
Secure bool
HttpOnly bool
Raw string
Unparsed []string // Raw text of unparsed attribute-value pairs
}我们来看一个例子,如何设置cookie
expiration := time.Now()
expiration = expiration.AddDate(1, 0, 0)
cookie := http.Cookie{Name: "username", Value: "astaxie", Expires: expiration}
http.SetCookie(w, &cookie)
Go读取cookie
上面的例子演示了如何设置cookie数据,我们这里来演示一下如何读取cookie
cookie, _ := r.Cookie("username")
fmt.Fprint(w, cookie)还有另外一种读取方式
for _, cookie := range r.Cookies() {
fmt.Fprint(w, cookie.Name)
}可以看到通过request获取cookie非常方便。
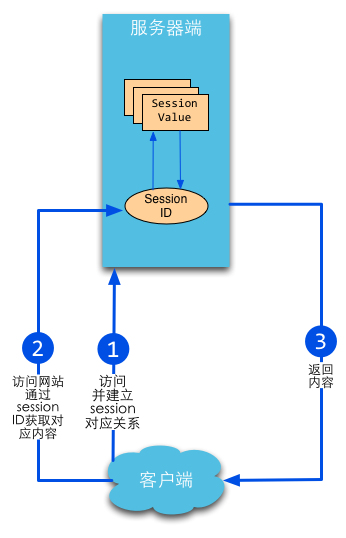
session
当session一词与网络协议相关联时,它又往往隐含了“面向连接”和/或“保持状态”这样两个含义。
session在Web开发环境下的语义又有了新的扩展,它的含义是指一类用来在客户端与服务器端之间保持状态的解决方案。有时候Session也用来指这种解决方案的存储结构。
session机制是一种服务器端的机制,服务器使用一种类似于散列表的结构(也可能就是使用散列表)来保存信息。
但程序需要为某个客户端的请求创建一个session的时候,服务器首先检查这个客户端的请求里是否包含了一个session标识-称为session id,如果已经包含一个session id则说明以前已经为此客户创建过session,服务器就按照session id把这个session检索出来使用(如果检索不到,可能会新建一个,这种情况可能出现在服务端已经删除了该用户对应的session对象,但用户人为地在请求的URL后面附加上一个JSESSION的参数)。如果客户请求不包含session id,则为此客户创建一个session并且同时生成一个与此session相关联的session id,这个session id将在本次响应中返回给客户端保存。
session机制本身并不复杂,然而其实现和配置上的灵活性却使得具体情况复杂多变。这也要求我们不能把仅仅某一次的经验或者某一个浏览器,服务器的经验当作普遍适用的
小结
session和cookie的目的相同,都是为了克服http协议无状态的缺陷,但完成的方法不同。session通过cookie,在客户端保存session id,而将用户的其他会话消息保存在服务端的session对象中,与此相对的,cookie需要将所有信息都保存在客户端。因此cookie存在着一定的安全隐患,例如本地cookie中保存的用户名密码被破译,或cookie被其他网站收集(例如:1. appA主动设置域B cookie,让域B cookie获取;2. XSS,在appA上通过javascript获取document.cookie,并传递给自己的appB)。
6.2 Go语言如何使用Session
目前Go标准包没有为session提供任何支持,这小节我们将会自己动手来实现go版本的session管理和创建。
Session创建过程
ession的基本原理是由服务器为每个会话维护一份信息数据,客户端和服务端依靠一个全局唯一的标识来访问这份数据,以达到交互的目的。当用户访问Web应用时,服务端程序会随需要创建session,这个过程可以概括为三个步骤:
- 生成全局唯一标识符(sessionid);
- 开辟数据存储空间。一般会在内存中创建相应的数据结构,但这种情况下,系统一旦掉电,所有的会话数据就会丢失,如果是电子商务类网站,这将造成严重的后果。所以为了解决这类问题,你可以将会话数据写到文件里或存储在数据库中,当然这样会增加I/O开销,但是它可以实现某种程度的session持久化,也更有利于session的共享;
- 将session的全局唯一标示符发送给客户端。
以上三个步骤中,最关键的是如何发送这个session的唯一标识这一步上。考虑到HTTP协议的定义,数据无非可以放到请求行、头域或Body里,所以一般来说会有两种常用的方式:cookie和URL重写。
- Cookie 服务端通过设置Set-cookie头就可以将session的标识符传送到客户端,而客户端此后的每一次请求都会带上这个标识符,另外一般包含session信息的cookie会将失效时间设置为0(会话cookie),即浏览器进程有效时间。至于浏览器怎么处理这个0,每个浏览器都有自己的方案,但差别都不会太大(一般体现在新建浏览器窗口的时候);
- URL重写 所谓URL重写,就是在返回给用户的页面里的所有的URL后面追加session标识符,这样用户在收到响应之后,无论点击响应页面里的哪个链接或提交表单,都会自动带上session标识符,从而就实现了会话的保持。虽然这种做法比较麻烦,但是,如果客户端禁用了cookie的话,此种方案将会是首选。
Go实现session管理
下面我们将结合session的生命周期(lifecycle),来实现go语言版本的session管理。
Session管理设计
session管理涉及到如下几个因素
- 全局session管理器
- 保证sessionid 的全局唯一性
- 为每个客户关联一个session
- session 的存储(可以存储到内存、文件、数据库等)
- session 过期处理
有过Web开发经验的读者知道,对Session的处理基本就 设置值、读取值、删除值以及获取当前sessionID这四个操作,所以我们的Session接口也就实现这四个操作。
这里有些代码跑不了(推测是修改了goroutine的部分),这本书是14年的用的go1.4,我在22年使用的是Go1.18,因此我决定从这里开始这本书就略读了,以后再用别的方式学习go web吧,有时候看书确实不如看视频合适,交互反馈太少了。其实这个属于我自己的判断错误,应该早点发现的!
6.4 预防session劫持
session劫持是一种广泛存在的比较严重的安全威胁,在session技术中,客户端和服务端通过session的标识符来维护会话, 但这个标识符很容易就能被嗅探到,从而被其他人利用.它是中间人攻击的一种类型。
本节将通过一个实例来演示会话劫持,希望通过这个实例,能让读者更好地理解session的本质。
session劫持过程
我们写了如下的代码来展示一个count计数器:
func count(w http.ResponseWriter, r *http.Request) {
sess := globalSessions.SessionStart(w, r)
ct := sess.Get("countnum")
if ct == nil {
sess.Set("countnum", 1)
} else {
sess.Set("countnum", (ct.(int) + 1))
}
t, _ := template.ParseFiles("count.gtpl")
w.Header().Set("Content-Type", "text/html")
t.Execute(w, sess.Get("countnum"))
}count.gtpl的代码如下所示:
Hi. Now count:{{.}}然后我们在浏览器里面刷新可以看到如下内容:
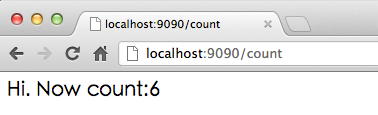
图6.4 浏览器端显示count数
随着刷新,数字将不断增长,当数字显示为6的时候,打开浏览器(以chrome为例)的cookie管理器,可以看到类似如下的信息:
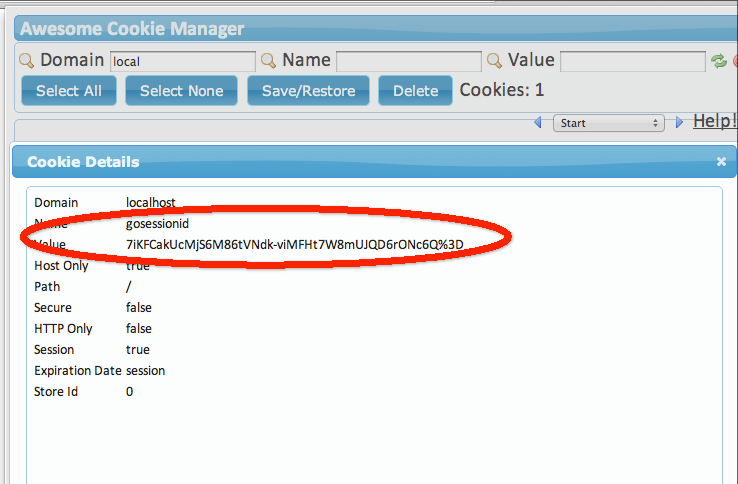
图6.5 获取浏览器端保存的cookie
下面这个步骤最为关键: 打开另一个浏览器(这里我打开了firefox浏览器),复制chrome地址栏里的地址到新打开的浏览器的地址栏中。然后打开firefox的cookie模拟插件,新建一个cookie,把按上图中cookie内容原样在firefox中重建一份:
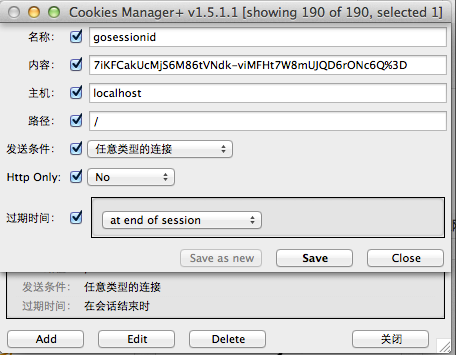
图6.6 模拟cookie
回车后,你将看到如下内容:
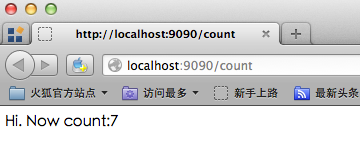
图6.7 劫持session成功
可以看到虽然换了浏览器,但是我们却获得了sessionID,然后模拟了cookie存储的过程。这个例子是在同一台计算机上做的,不过即使换用两台来做,其结果仍然一样。此时如果交替点击两个浏览器里的链接你会发现它们其实操纵的是同一个计数器。不必惊讶,此处firefox盗用了chrome和goserver之间的维持会话的钥匙,即gosessionid,这是一种类型的“会话劫持”。在goserver看来,它从http请求中得到了一个gosessionid,由于HTTP协议的无状态性,它无法得知这个gosessionid是从chrome那里“劫持”来的,它依然会去查找对应的session,并执行相关计算。与此同时 chrome也无法得知自己保持的会话已经被“劫持”
7
7.4 模板处理
在Go语言中,我们使用template包来进行模板处理,使用类似Parse、ParseFile、Execute等方法从文件或者字符串加载模板,然后执行类似上面图片展示的模板的merge操作。请看下面的例子:
func handler(w http.ResponseWriter, r *http.Request) {
t := template.New("some template") //创建一个模板
t, _ = t.ParseFiles("tmpl/welcome.html", nil) //解析模板文件
user := GetUser() //获取当前用户信息
t.Execute(w, user) //执行模板的merger操作
}通过上面的例子我们可以看到Go语言的模板操作非常的简单方便,和其他语言的模板处理类似,都是先获取数据,然后渲染数据。
为了演示和测试代码的方便,我们在接下来的例子中采用如下格式的代码
- 使用Parse代替ParseFiles,因为Parse可以直接测试一个字符串,而不需要额外的文件
- 不使用handler来写演示代码,而是每个测试一个main,方便测试
- 使用
os.Stdout代替http.ResponseWriter,因为os.Stdout实现了io.Writer接口
字段操作
Go语言的模板通过{{}}来包含需要在渲染时被替换的字段,{{.}}表示当前的对象,这和Java或者C++中的this类似,如果要访问当前对象的字段通过{{.FieldName}},但是需要注意一点:这个字段必须是导出的(字段首字母必须是大写的),否则在渲染的时候就会报错
package main
import (
"html/template"
"os"
)
type Person struct {
UserName string
}
func main() {
t := template.New("fieldname example")
t, _ = t.Parse("hello {{.UserName}}!")
p := Person{UserName: "Astaxie"}
t.Execute(os.Stdout, p)
}输出嵌套字段内容
上面我们例子展示了如何针对一个对象的字段输出,那么如果字段里面还有对象,如何来循环的输出这些内容呢?我们可以使用{{with …}}…{{end}}和{{range …}}{{end}}来进行数据的输出。
- function range(start, stop, step) { if (typeof stop === 'undefined') { stop = start; start = 0; step = 1; } else if (!step) { step = 1; } var arr = []; if (step > 0) { for (var i = start; i < stop; i += step) { arr.push(i); } } else { for (var _i = start; _i > stop; _i += step) { // eslint-disable-line for-direction arr.push(_i); } } return arr; } 这个和Go语法里面的range类似,循环操作数据
- 操作是指当前对象的值,类似上下文的概念
package main
import (
"html/template"
"os"
)
type Friend struct {
Fname string
}
type Person struct {
UserName string
Emails []string
Friends []*Friend
}
func main() {
f1 := Friend{Fname: "minux.ma"}
f2 := Friend{Fname: "xushiwei"}
t := template.New("fieldname example")
t, _ = t.Parse(`hello {{.UserName}}!
{{range .Emails}}
an email {{.}}
{{end}}
{{with .Friends}}
{{range .}}
my friend name is {{.Fname}}
{{end}}
{{end}}
`)
p := Person{UserName: "Astaxie",
Emails: []string{"astaxie@beego.me", "astaxie@gmail.com"},
Friends: []*Friend{&f1, &f2}}
t.Execute(os.Stdout, p)
}条件处理
在Go模板里面如果需要进行条件判断,那么我们可以使用和Go语言的if-else语法类似的方式来处理,如果pipeline为空,那么if就认为是false,下面的例子展示了如何使用if-else语法:
package main
import (
"os"
"text/template"
)
func main() {
tEmpty := template.New("template test")
tEmpty = template.Must(tEmpty.Parse("空 pipeline if demo: {{if ``}} 不会输出. {{end}}\n"))
tEmpty.Execute(os.Stdout, nil)
tWithValue := template.New("template test")
tWithValue = template.Must(tWithValue.Parse("不为空的 pipeline if demo: {{if `anything`}} 我有内容,我会输出. {{end}}\n"))
tWithValue.Execute(os.Stdout, nil)
tIfElse := template.New("template test")
tIfElse = template.Must(tIfElse.Parse("if-else demo: {{if `anything`}} if部分 {{else}} else部分.{{end}}\n"))
tIfElse.Execute(os.Stdout, nil)
}通过上面的演示代码我们知道if-else语法相当的简单,在使用过程中很容易集成到我们的模板代码中。
注意:if里面无法使用条件判断,例如.Mail==”astaxie@gmail.com”,这样的判断是不正确的,if里面只能是bool值
pipelines
Unix用户已经很熟悉什么是pipe了,ls | grep "beego"类似这样的语法你是不是经常使用,过滤当前目录下面的文件,显示含有”beego”的数据,表达的意思就是前面的输出可以当做后面的输入,最后显示我们想要的数据,而Go语言模板最强大的一点就是支持pipe数据,在Go语言里面任何{{}}里面的都是pipelines数据,例如我们上面输出的email里面如果还有一些可能引起XSS注入的,那么我们如何来进行转化呢?
{{. | html}}在email输出的地方我们可以采用如上方式可以把输出全部转化html的实体,上面的这种方式和我们平常写Unix的方式是不是一模一样,操作起来相当的简便,调用其他的函数也是类似的方式。
模板函数
模板在输出对象的字段值时,采用了fmt包把对象转化成了字符串。但是有时候我们的需求可能不是这样的,例如有时候我们为了防止垃圾邮件发送者通过采集网页的方式来发送给我们的邮箱信息,我们希望把@替换成at例如:astaxie at beego.me,如果要实现这样的功能,我们就需要自定义函数来做这个功能。
每一个模板函数都有一个唯一值的名字,然后与一个Go函数关联,通过如下的方式来关联
type FuncMap map[string]interface{}例如,如果我们想要的email函数的模板函数名是emailDeal,它关联的Go函数名称是EmailDealWith,那么我们可以通过下面的方式来注册这个函数
t = t.Funcs(template.FuncMap{"emailDeal": EmailDealWith})EmailDealWith这个函数的参数和返回值定义如下:
func EmailDealWith(args …interface{}) string我们来看下面的实现例子:
package main
import (
"fmt"
"html/template"
"os"
"strings"
)
type Friend struct {
Fname string
}
type Person struct {
UserName string
Emails []string
Friends []*Friend
}
func EmailDealWith(args ...interface{}) string {
ok := false
var s string
if len(args) == 1 {
s, ok = args[0].(string)
}
if !ok {
s = fmt.Sprint(args...)
}
// find the @ symbol
substrs := strings.Split(s, "@")
if len(substrs) != 2 {
return s
}
// replace the @ by " at "
return (substrs[0] + " at " + substrs[1])
}
func main() {
f1 := Friend{Fname: "minux.ma"}
f2 := Friend{Fname: "xushiwei"}
t := template.New("fieldname example")
t = t.Funcs(template.FuncMap{"emailDeal": EmailDealWith})
t, _ = t.Parse(`hello {{.UserName}}!
{{range .Emails}}
an emails {{.|emailDeal}}
{{end}}
{{with .Friends}}
{{range .}}
my friend name is {{.Fname}}
{{end}}
{{end}}
`)
p := Person{UserName: "Astaxie",
Emails: []string{"astaxie@beego.me", "astaxie@gmail.com"},
Friends: []*Friend{&f1, &f2}}
t.Execute(os.Stdout, p)
}上面演示了如何自定义函数,其实,在模板包内部已经有内置的实现函数,下面代码截取自模板包里面
var builtins = FuncMap{
"and": and,
"call": call,
"html": HTMLEscaper,
"index": index,
"js": JSEscaper,
"len": length,
"not": not,
"or": or,
"print": fmt.Sprint,
"printf": fmt.Sprintf,
"println": fmt.Sprintln,
"urlquery": URLQueryEscaper,
}Must操作
模板包里面有一个函数Must,它的作用是检测模板是否正确,例如大括号是否匹配,注释是否正确的关闭,变量是否正确的书写。接下来我们演示一个例子,用Must来判断模板是否正确:
package main
import (
"fmt"
"text/template"
)
func main() {
tOk := template.New("first")
template.Must(tOk.Parse(" some static text /* and a comment */"))
fmt.Println("The first one parsed OK.")
template.Must(template.New("second").Parse("some static text {{ .Name }}"))
fmt.Println("The second one parsed OK.")
fmt.Println("The next one ought to fail.")
tErr := template.New("check parse error with Must")
template.Must(tErr.Parse(" some static text {{ .Name }"))
}讲输出如下内容
The first one parsed OK.
The second one parsed OK.
The next one ought to fail.
panic: template: check parse error with Must:1: unexpected "}" in command8 Web服务
Web服务背后的关键在于平台的无关性,你可以运行你的服务在Linux系统,可以与其他Windows的asp.net程序交互,同样的,也可以通过同一个接口和运行在FreeBSD上面的JSP无障碍地通信。
目前主流的有如下几种Web服务:REST、SOAP。
REST请求是很直观的,因为REST是基于HTTP协议的一个补充,他的每一次请求都是一个HTTP请求,然后根据不同的method来处理不同的逻辑,很多Web开发者都熟悉HTTP协议,所以学习REST是一件比较容易的事情。所以我们在8.3小节讲详细的讲解如何在Go语言中来实现REST方式。
SOAP是W3C在跨网络信息传递和远程计算机函数调用方面的一个标准。但是SOAP非常复杂,其完整的规范篇幅很长,而且内容仍然在增加。Go语言是以简单著称,所以我们不会介绍SOAP这样复杂的东西。而Go语言提供了一种天生性能很不错,开发起来很方便的RPC机制,我们将会在8.4小节详细介绍如何使用Go语言来实现RPC。
8.3 REST
RESTful,是目前最为流行的一种互联网软件架构。因为它结构清晰、符合标准、易于理解、扩展方便,所以正得到越来越多网站的采用。
REST就是根据不同的method访问同一个资源的时候实现不同的逻辑处理。
9 安全与加密
很多Web应用程序中的安全问题都是由于轻信了第三方提供的数据造成的。比如对于用户的输入数据,在对其进行验证之前都应该将其视为不安全的数据。如果直接把这些不安全的数据输出到客户端,就可能造成跨站脚本攻击(XSS)的问题。如果把不安全的数据用于数据库查询,那么就可能造成SQL注入问题,
在使用第三方提供的数据,包括用户提供的数据时,首先检验这些数据的合法性非常重要,这个过程叫做过滤,我们将在9.2小节介绍如何保证对所有输入的数据进行过滤处理。
过滤输入和转义输出并不能解决所有的安全问题,我们将会在9.1讲解的CSRF攻击,会导致受骗者发送攻击者指定的请求从而造成一些破坏。
与安全加密相关的,能够增强我们的Web应用程序的强大手段就是加密,CSDN泄密事件就是因为密码保存的是明文,使得攻击拿手库之后就可以直接实施一些破坏行为了。不过,和其他工具一样,加密手段也必须运用得当。我们将在9.5小节介绍如何存储密码,如何让密码存储的安全。
加密的本质就是扰乱数据,某些不可恢复的数据扰乱我们称为单向加密或者散列算法。另外还有一种双向加密方式,也就是可以对加密后的数据进行解密。我们将会在9.6小节介绍如何实现这种双向加密方式。
9.1 预防CSRF攻击
什么是CSRF
CSRF(Cross-site request forgery),中文名称:跨站请求伪造,也被称为:one click attack/session riding,缩写为:CSRF/XSRF。
那么CSRF到底能够干嘛呢?你可以这样简单的理解:攻击者可以盗用你的登陆信息,以你的身份模拟发送各种请求。攻击者只要借助少许的社会工程学的诡计,例如通过QQ等聊天软件发送的链接(有些还伪装成短域名,用户无法分辨),攻击者就能迫使Web应用的用户去执行攻击者预设的操作。例如,当用户登录网络银行去查看其存款余额,在他没有退出时,就点击了一个QQ好友发来的链接,那么该用户银行帐户中的资金就有可能被转移到攻击者指定的帐户中。
所以遇到CSRF攻击时,将对终端用户的数据和操作指令构成严重的威胁;当受攻击的终端用户具有管理员帐户的时候,CSRF攻击将危及整个Web应用程序。
CSRF的原理
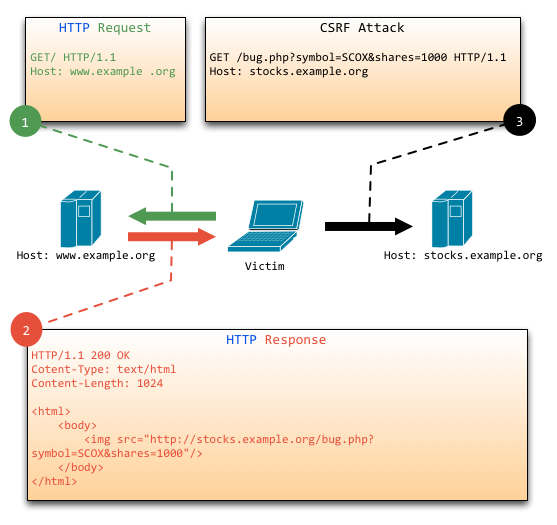
从上图可以看出,要完成一次CSRF攻击,受害者必须依次完成两个步骤 :
- 1.登录受信任网站A,并在本地生成Cookie 。
- 2.在不退出A的情况下,访问危险网站B。
读者也许会问:“如果我不满足以上两个条件中的任意一个,就不会受到CSRF的攻击”。是的,确实如此,但你不能保证以下情况不会发生:
- 你不能保证你登录了一个网站后,不再打开一个tab页面并访问另外的网站,特别现在浏览器都是支持多tab的。
- 你不能保证你关闭浏览器了后,你本地的Cookie立刻过期,你上次的会话已经结束。
- 上图中所谓的攻击网站,可能是一个存在其他漏洞的可信任的经常被人访问的网站。
CSRF攻击主要是因为Web的隐式身份验证机制,Web的身份验证机制虽然可以保证一个请求是来自于某个用户的浏览器,但却无法保证该请求是用户批准发送的。
如何预防CSRF
CSRF的防御可以从服务端和客户端两方面着手,防御效果是从服务端着手效果比较好,现在一般的CSRF防御也都在服务端进行。
服务端的预防CSRF攻击的方式方法有多种,但思想上都是差不多的,主要从以下2个方面入手:
- 1、正确使用GET,POST和Cookie;
- 2、在非GET请求中增加伪随机数;
一般而言,普通的Web应用都是以GET、POST为主,还有一种请求是Cookie方式。我们一般都是按照如下方式设计应用:
1、GET常用在查看,列举,展示等不需要改变资源属性的时候;
2、POST常用在下达订单,改变一个资源的属性或者做其他一些事情;
9.4 避免SQL注入
什么是SQL注入
SQL注入攻击(SQL Injection),简称注入攻击,是Web开发中最常见的一种安全漏洞。可以用它来从数据库获取敏感信息,或者利用数据库的特性执行添加用户,导出文件等一系列恶意操作,甚至有可能获取数据库乃至系统用户最高权限。
而造成SQL注入的原因是因为程序没有有效过滤用户的输入,使攻击者成功的向服务器提交恶意的SQL查询代码,程序在接收后错误的将攻击者的输入作为查询语句的一部分执行,导致原始的查询逻辑被改变,额外的执行了攻击者精心构造的恶意代码。
SQL注入实例
很多Web开发者没有意识到SQL查询是可以被篡改的,从而把SQL查询当作可信任的命令。殊不知,SQL查询是可以绕开访问控制,从而绕过身份验证和权限检查的。更有甚者,有可能通过SQL查询去运行主机系统级的命令。
下面将通过一些真实的例子来详细讲解SQL注入的方式。
考虑以下简单的登录表单:
<form action="/login" method="POST">
<p>Username: <input type="text" name="username" /></p>
<p>Password: <input type="password" name="password" /></p>
<p><input type="submit" value="登陆" /></p>
</form>我们的处理里面的SQL可能是这样的:
username:=r.Form.Get("username")
password:=r.Form.Get("password")
sql:="SELECT * FROM user WHERE username='"+username+"' AND password='"+password+"'"如果用户的输入的用户名如下,密码任意
myuser’ or ‘foo’ = ‘foo’ —
那么我们的SQL变成了如下所示:
SELECT *
FROM user
WHERE username = ‘myuser’ or ‘foo’==’foo’ —‘’ AND password=’xxx’
在SQL里面—是注释标记,所以查询语句会在此中断。这就让攻击者在不知道任何合法用户名和密码的情况下成功登录了。
PS:这行sql注入确实牛逼,hexo博客里的用来高亮代码的prismJs在这里报错了,查了很久才查出来,索性就在这句话里不用高亮了(狗头,看似半小时搞完,实则好几个月才解决掉)
10 国际化与本地化
10.1 设置默认地区
Locale是一组描述世界上某一特定区域文本格式和语言习惯的设置的集合。locale名通常由三个部分组成:第一部分,是一个强制性的,表示语言的缩写,例如”en”表示英文或”zh”表示中文。第二部分,跟在一个下划线之后,是一个可选的国家说明符,用于区分讲同一种语言的不同国家,例如”en_US”表示美国英语,而”en_UK”表示英国英语。最后一部分,跟在一个句点之后,是可选的字符集说明符,例如”zh_CN.gb2312”表示中国使用gb2312字符集。
设置Locale的办法这一就是在应用运行的时候采用域名分级的方式,例如,我们采用www.asta.com当做我们的英文站(默认站),而把域名www.asta.cn当做中文站。
但是我们一般开发Web应用的时候不会采用这种方式,因为首先域名成本比较高,开发一个Locale就需要一个域名,而且往往统一名称的域名不一定能申请的到,其次我们不愿意为每个站点去本地化一个配置,而更多的是采用url后面带参数的方式
从域名参数设置Locale
目前最常用的设置Locale的方式是在URL里面带上参数,例如www.asta.com/hello?locale=zh或者www.asta.com/zh/hello。这样我们就可以设置地区:i18n.SetLocale(params["locale"])
本地化文本消息
本信息是编写Web应用中最常用到的,也是本地化资源中最多的信息,想要以适合本地语言的方式来显示文本信息,可行的一种方案是:建立需要的语言相应的map来维护一个key-value的关系,在输出之前按需从适合的map中去获取相应的文本,如下是一个简单的示例:
package main
import "fmt"
var locales map[string]map[string]string
func main() {
locales = make(map[string]map[string]string, 2)
en := make(map[string]string, 10)
en["pea"] = "pea"
en["bean"] = "bean"
locales["en"] = en
cn := make(map[string]string, 10)
cn["pea"] = "豌豆"
cn["bean"] = "毛豆"
locales["zh-CN"] = cn
lang := "zh-CN"
fmt.Println(msg(lang, "pea"))
fmt.Println(msg(lang, "bean"))
}
func msg(locale, key string) string {
if v, ok := locales[locale]; ok {
if v2, ok := v[key]; ok {
return v2
}
}
return ""
}本地化视图和资源
我们可能会根据Locale的不同来展示视图,这些视图包含不同的图片、css、js等各种静态资源。那么应如何来处理这些信息呢?首先我们应按locale来组织文件信息,请看下面的文件目录安排:
views
|--en //英文模板
|--images //存储图片信息
|--js //存储JS文件
|--css //存储css文件
index.tpl //用户首页
login.tpl //登陆首页
|--zh-CN //中文模板
|--images
|--js
|--css
index.tpl
login.tpl有了这个目录结构后我们就可以在渲染的地方这样来实现代码:
s1, _ := template.ParseFiles("views"+lang+"index.tpl")
VV.Lang=lang
s1.Execute(os.Stdout, VV)而对于里面的index.tpl里面的资源设置如下:
// js文件
<script type="text/javascript" src="views/{{.VV.Lang}}/js/jquery/jquery-1.8.0.min.js"></script>
// css文件
<link href="views/{{.VV.Lang}}/css/bootstrap-responsive.min.css" rel="stylesheet">
// 图片文件
<img src="views/{{.VV.Lang}}/images/btn.png">采用这种方式来本地化视图以及资源时,我们就可以很容易的进行扩展了。
本小节介绍了如何使用及存储本地资源,有时需要通过转换函数来实现,有时通过lang来设置,但是最终都是通过key-value的方式来存储Locale对应的数据,在需要时取出相应于Locale的信息后,如果是文本信息就直接输出,如果是时间日期或者货币,则需要先通过fmt.Printf或其他格式化函数来处理,而对于不同Locale的视图和资源则是最简单的,只要在路径里面增加lang就可以实现了。
10.3 国际化站点
管理多个本地包
在开发一个应用的时候,首先我们要决定是只支持一种语言,还是多种语言,如果要支持多种语言,我们则需要制定一个组织结构,以方便将来更多语言的添加。在此我们设计如下:Locale有关的文件放置在config/locales下,假设你要支持中文和英文,那么你需要在这个文件夹下放置en.json和zh.json。大概的内容如下所示:
# zh.json
{
"zh": {
"submit": "提交",
"create": "创建"
}
}
#en.json
{
"en": {
"submit": "Submit",
"create": "Create"
}
}为了支持国际化,在此我们使用了一个国际化相关的包——go-i18n,首先我们向go-i18n包注册config/locales这个目录,以加载所有的locale文件
Tr:=i18n.NewLocale()
Tr.LoadPath("config/locales")11 错误处理,调试和测试
在C语言里面是通过返回-1或者NULL之类的信息来表示错误,但是对于使用者来说,不查看相应的API说明文档,根本搞不清楚这个返回值究竟代表什么意思,比如:返回0是成功,还是失败,而Go定义了一个叫做error的类型,来显式表达错误。在使用时,通过把返回的error变量与nil的比较,来判定操作是否成功
11.2 使用GDB调试
开发程序过程中调试代码是开发者经常要做的一件事情,Go语言不像PHP、Python等动态语言,只要修改不需要编译就可以直接输出,而且可以动态的在运行环境下打印数据
12 部署与维护
13 如何设计一个WEB框架
13.1 项目规划
应用程序流程图
博客系统是基于模型-视图-控制器这一设计模式的。MVC是一种将应用程序的逻辑层和表现层进行分离的结构方式。在实践中,由于表现层从Go中分离了出来,所以它允许你的网页中只包含很少的脚本。
- 模型 (Model) 代表数据结构。通常来说,模型类将包含取出、插入、更新数据库资料等这些功能。
- 视图 (View) 是展示给用户的信息的结构及样式。一个视图通常是一个网页,但是在Go中,一个视图也可以是一个页面片段,如页头、页尾。它还可以是一个 RSS 页面,或其它类型的“页面”,Go实现的template包已经很好的实现了View层中的部分功能。
- 控制器 (Controller) 是模型、视图以及其他任何处理HTTP请求所必须的资源之间的中介,并生成网页。
下图显示了项目设计中框架的数据流是如何贯穿整个系统:
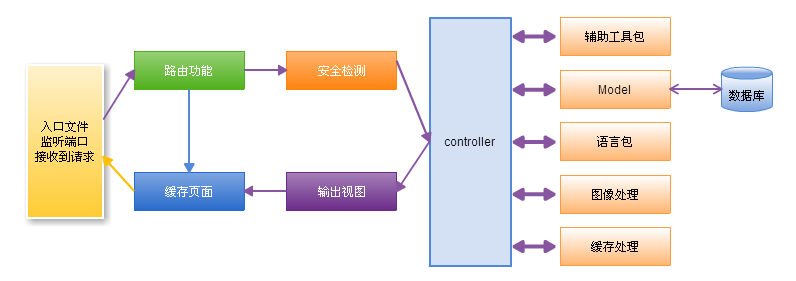
图13.3 框架的数据流
- main.go作为应用入口,初始化一些运行博客所需要的基本资源,配置信息,监听端口。
- 路由功能检查HTTP请求,根据URL以及method来确定谁(控制层)来处理请求的转发资源。
- 如果缓存文件存在,它将绕过通常的流程执行,被直接发送给浏览器。
- 安全检测:应用程序控制器调用之前,HTTP请求和任一用户提交的数据将被过滤。
- 控制器装载模型、核心库、辅助函数,以及任何处理特定请求所需的其它资源,控制器主要负责处理业务逻辑。
- 输出视图层中渲染好的即将发送到Web浏览器中的内容。如果开启缓存,视图首先被缓存,将用于以后的常规请求。
目录结构
根据上面的应用程序流程设计,博客的目录结构设计如下:
|——main.go 入口文件
|——conf 配置文件和处理模块
|——controllers 控制器入口
|——models 数据库处理模块
|——utils 辅助函数库
|——static 静态文件目录
|——views 视图库框架设计
为了实现博客的快速搭建,打算基于上面的流程设计开发一个最小化的框架,框架包括路由功能、支持REST的控制器、自动化的模板渲染,日志系统、配置管理等。
13.2 自定义路由器设计
Go默认的路由添加是通过函数http.Handle和http.HandleFunc等来添加,底层都是调用了DefaultServeMux.Handle(pattern string, handler Handler),这个函数会把路由信息存储在一个map信息中map[string]muxEntry