阅读论文
《Structure-aware Visualization Retrieval》
- 来源:CHI 2022 (Honorable Mention)
- 总结:这篇文章主要是基于图片的结构(例如:SVG的结构)去做可视化搜索(类似以图搜图)
- 现有可视化检索方法主要关注可视化的视觉外观,而忽略了基于 SVG
的可视化中固有的结构信息,其描述了视觉元素之间的空间和层次关系(这种结构信息可以勾勒出视觉元素之间的空间和层次关系,并从一个新的角度描述可视化的特征。)。这篇文章提出了一种结构感知的可视化检索方法,通过综合考虑视觉和结构信息来提高检索的性能。 - 主要做法如下:
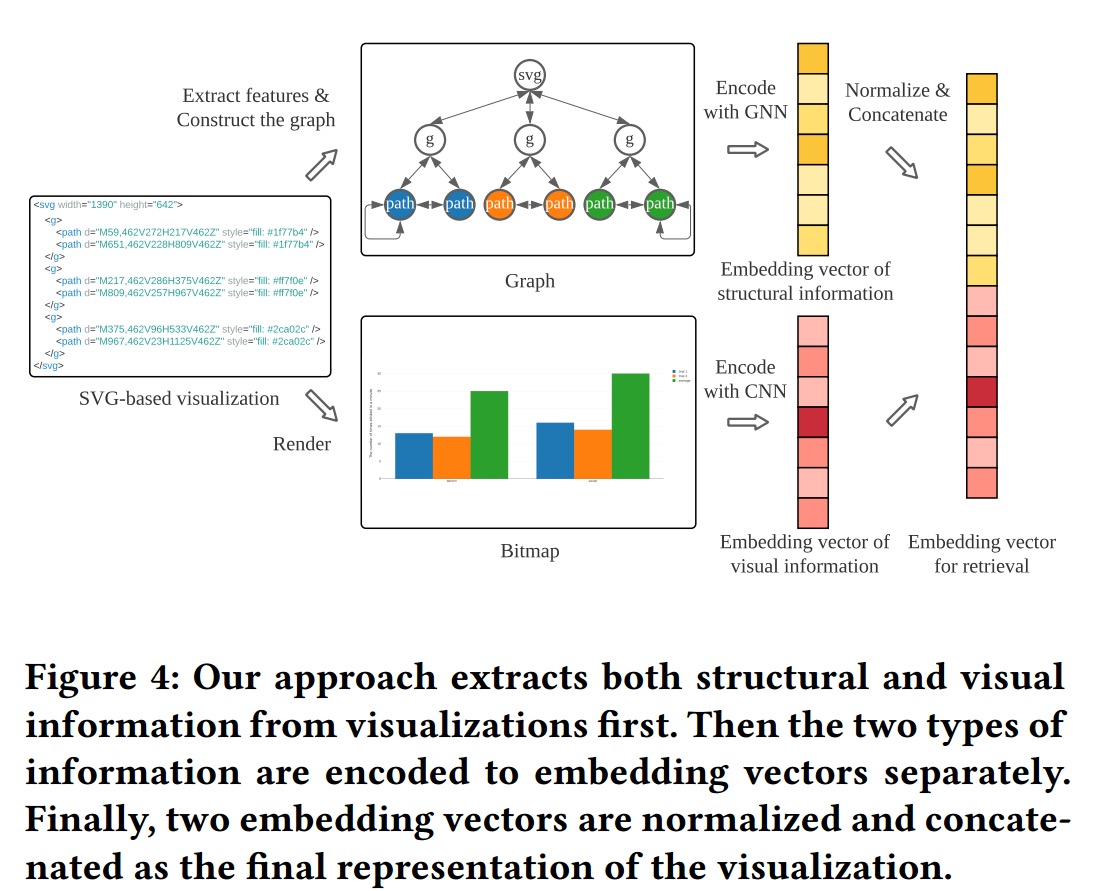
- 对我的启发:把SVG中的结构信息,通过GNN,用到了某任务上。
- Others: 他把SVG中的结构(树)通过构建双向边,自环(好像还有点别的trick),拓展成可以用来GNN的graph了(在section5.1的Graph
Construction里和figure5)
Adaptive wavelet distillation from neural networks through interpretations
- 期刊:Advances in Neural Information Processing Systems
- 这个文章提出了自适应小波蒸馏(AWD, adaptive wavelet distillation )方法。 这个方法把信息从预先训练的监督模型(例如
DNN)中提取到小波变换中(wavelet transform:用来在时间(空间)和频域中描述信号,在物理和生物应用比较多). - 总结:AWD 根据传统小波解释 DNN
- 论文做的事:
- 改造输入,以帮助模型得到更好的输出。把‘DNN的知识’转移到这个‘改造输入’里。
- 是个迭代过程 dnn的输出 迭代改变输入
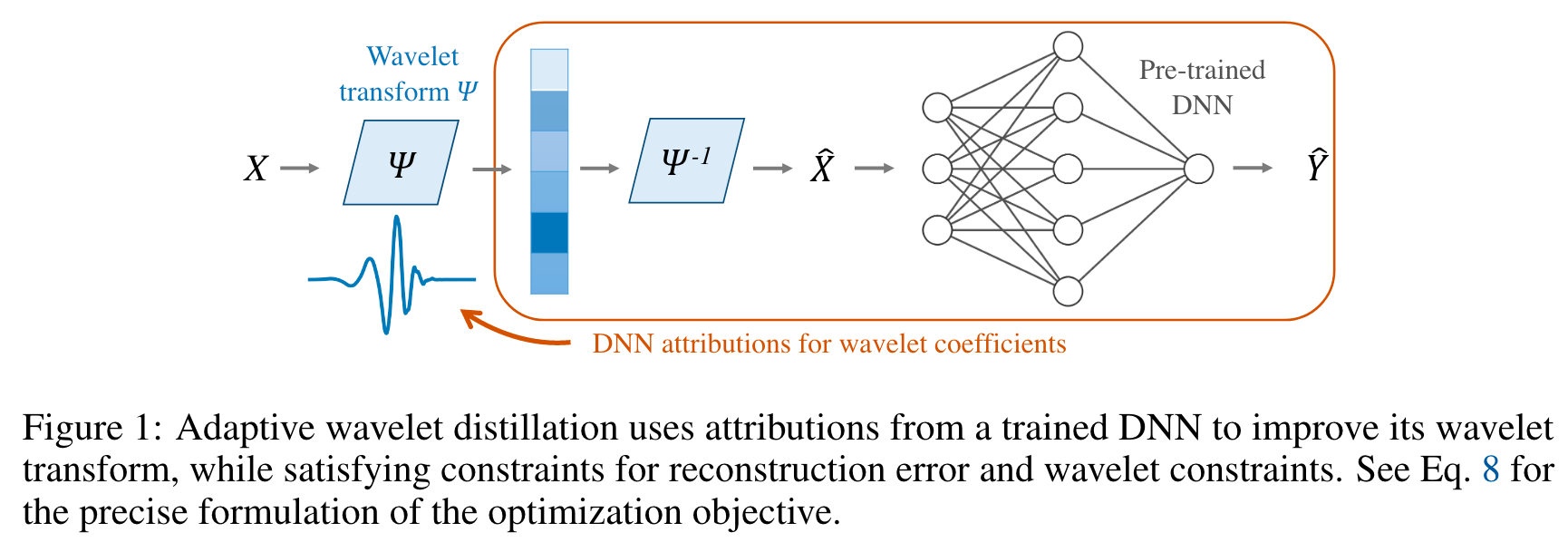
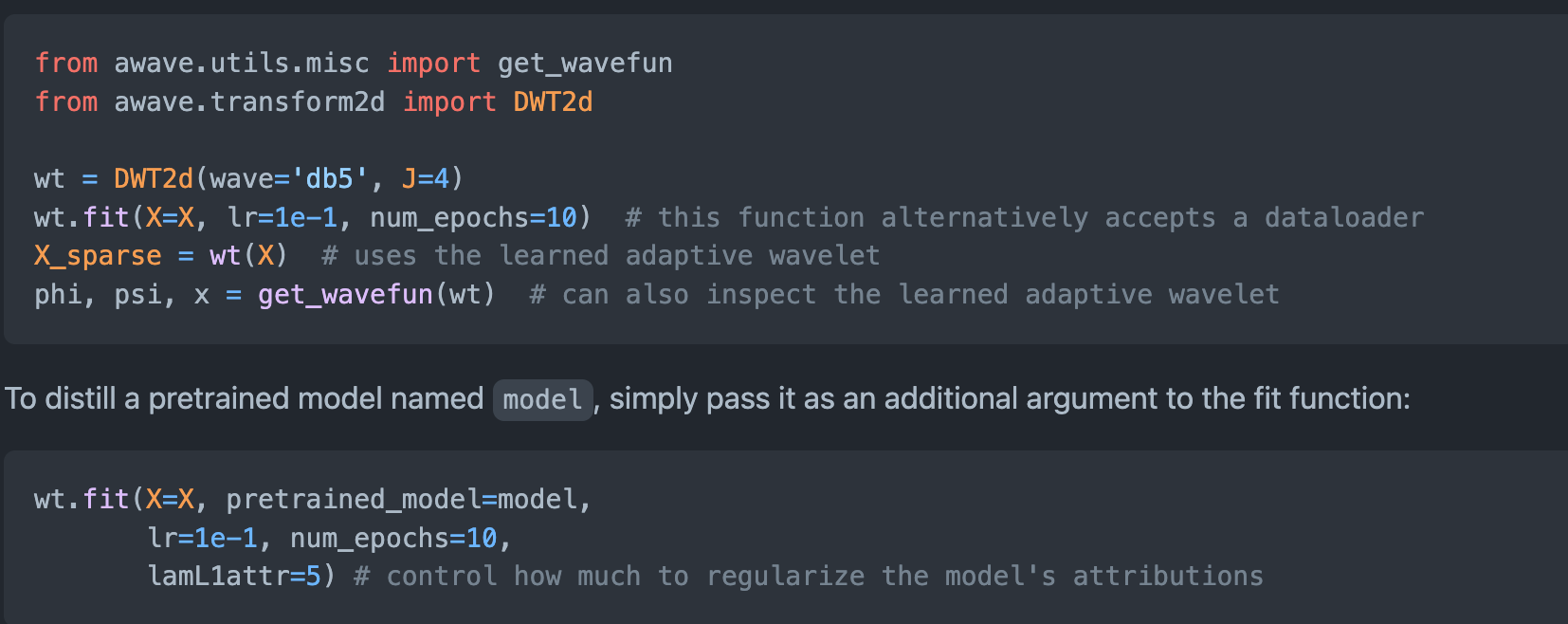
- 这个图和这个代码是对应的
《Hierarchical Attention Propagation for Healthcare Representation Learning》
- 会议:KDD2020
Medical ontologies are widely used to represent and organize medical terminologies.简单来说,本文要处理的数据是一个给疾病分类并不断细化的有层次的树。
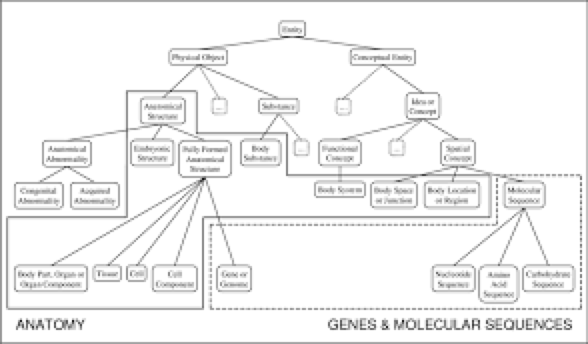
原来有一种Gram的注意力机制方法,来训练得到这个树上的每个节点的向量,根据这个向量来进行表示。
本文提出了一种HAP方法(也就是从上到下扫描+从下到上扫描)上的注意力机制方法,来训练得到这个树上的每个节点的向量,根据这个向量来进行表示。这个方法相比Gram在Medical
ontologies的表示能力更强,这篇文章主要说这个。
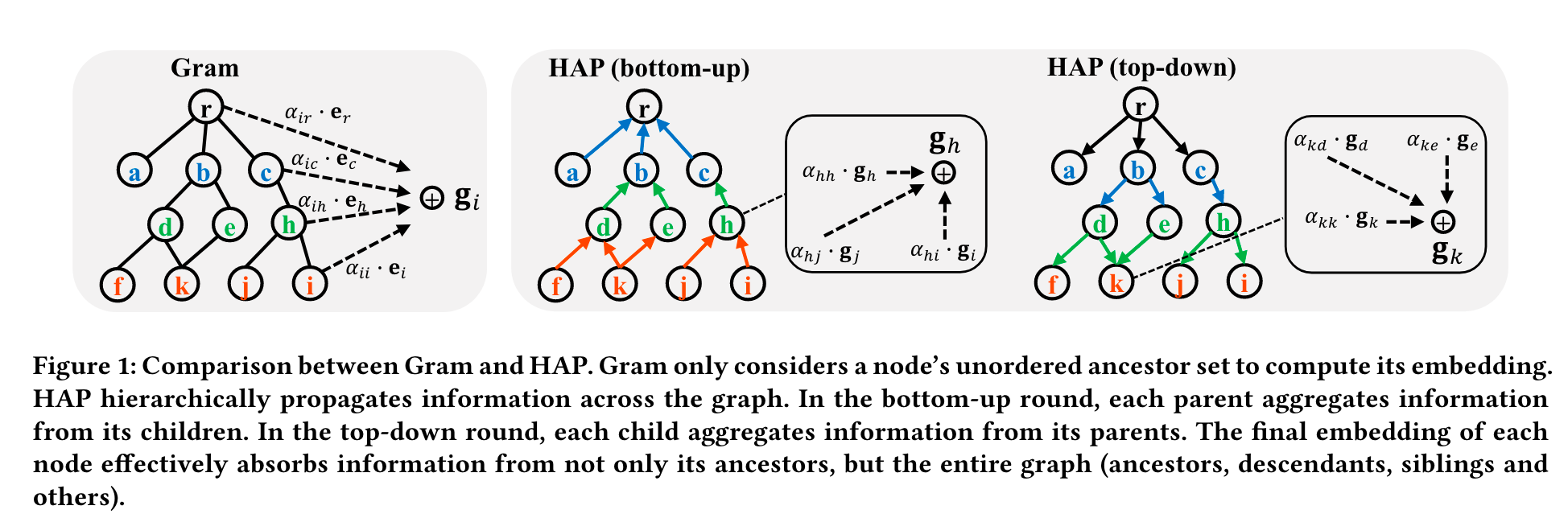
具体来说,他做的事情就是(比如说,在这颗树上,有很多节点,到了某个节点,比如说这个节点是’着凉‘,然后这个节点有几个儿子节点:’感冒’和其他疾病。而其他节点也可能有儿子节点包含’感冒‘)。文章要做的就是根据每个节点的向量表示,判断病人今天感冒,明天的症状是什么。
EpiMob: Interactive Visual Analytics of Citywide Human Mobility Restrictions for Epidemic Control
来源:TVCG2022
可视化设计:
EpiMob是#第一个#利用全市人口流动数据和城市POI数据,以细粒度时空粒度提供流行病控制政策模拟的交互式可视化分析系统。
该系统,基于东京人轨迹数据和东京城市 POI
数据(可以理解为:哪里人多,哪里人少),以交互方式模拟人类流动性和感染状态的变化,以响应特定限制政策或政策组合(有这三个:区域封锁、远程办公、筛查)的实施。用户可以方便地为不同的移动限制策略指定空间和时间范围。该工作模拟的是#东京#的疫情情况。
工作比较:
大多数类似工作只提供了高空间尺度上的模拟,将城市视为最小的实施单位。(背景:随着疫情正常化,全市范围内的细粒度疫情防控可能是在维持正常生计的同时抑制感染传播的更合适途径)因此本文针对的是东京市的模拟,以城市为最大尺度。
相比其他疫情控制的研究,主要区别如下:
- 他们通过直接参数设置来指定政策,例如,通过手动调整迁移率来模拟旅行限制政策。本研究侧重于交互式设置和模拟政策,强调何时何地实施何种政策。
- 这项工作面向全市流行病控制,在政策实施中引入了更精细的粒度。相比之下,上述大部分工作的设计粒度都比较粗。
难点(即论文的部分contribution来源):
与更高的空间尺度(即国家到全球)相比,全市决策场景涉及地方控制政策,需要考虑复杂的城市内部的特征。
需要同时考虑时间和空间(需要平衡复杂性与计算效率的模型)
模拟条件的多样性和复杂性,即限制政策的类型、强度和时空范围是多样的。(用户体验需要与参数复杂性相平衡)
模型:
提出了一种新的基于轨迹的流行病模型#,来模拟流行病的细粒度传播。
对轨迹数据(对每个人是:三元组[时间,维度,精度]的序列)进行插值,以获得更详细的数据,因为是根据POI的细粒度来做的模拟,所以是Grid-mapped
Interpolated Human 。“Two-stage Epidemic Simulation”
- ①“Restricted Mobility Generation” 设置隔离政策
- ②“Epidemic Simulation with Restricted Mobility” 设置疾病参数。
这体现了仿真机制的可扩展性。开发者可以在第 1 阶段设计新的限制策略,并在第 2 阶段使用其他流行病模型。
- 将传统的 SEIR 模型扩展到基于网格的模型。
①对相关传染参数进行了求和累加。
②与经典的 SEIR 模型不同,本模型表现出随机性。给定 (Γ, Θ),模拟结果 E_sim 关于感染事件的总数及其发生时间和位置是不稳定的。因此,需要多次模拟。在本研究中,重复次数
m 设置为 100。此外,重复模拟采用并行计算,以确保计算效率。
- “Replacement-Based Restricted Mobility Model”
当用户受到移动限制策略的影响时,移动行为也会受到相应的影响。例如,用户每个周末都会光顾购物中心。商场在某一天lockdown,用户将不会去这个地方。
将受影响的轨迹替换为不受影响的轨迹,称为轨迹替换策略。本文对每个限制策略(Telecommuting,regional Lockdown, Screening)
详细说明了替换方法。
limitations and Future work:
对于封控policy的种类还可以增加和细化讨论,
增加更多疫情的传染程度,疾病程度,症状等疾病性质
只讨论了怎么增,没有怎么减(假阳性; 或者阳性一段时间后,不再具有传染性)
可视化界面上可以有医疗资源的分布,以及医疗资源对于疫情增长的影响。
本文是根据公开的东京人的轨迹数据来做的对东京情况的可视化,但是数据集本身是有偏差的,只能进行有限的纠偏(例如,年龄:年轻人会用智能手机记录数据,老年人很少用;时间;空间)。如果做成可随时导入新数据会更好。
拓展性:本文做的是东京,怎么拓展到其他地方。怎么拓展到更大的地区,更多场景。论文中的建议是:‘可能需要用于参数迁移的自动参数校准机制或机器学习方法来增强系统的适用性’
Others
文中给出一些样例(sec7.1),来说明在哪些情况下该怎么决策,然后新闻验证他的结论。
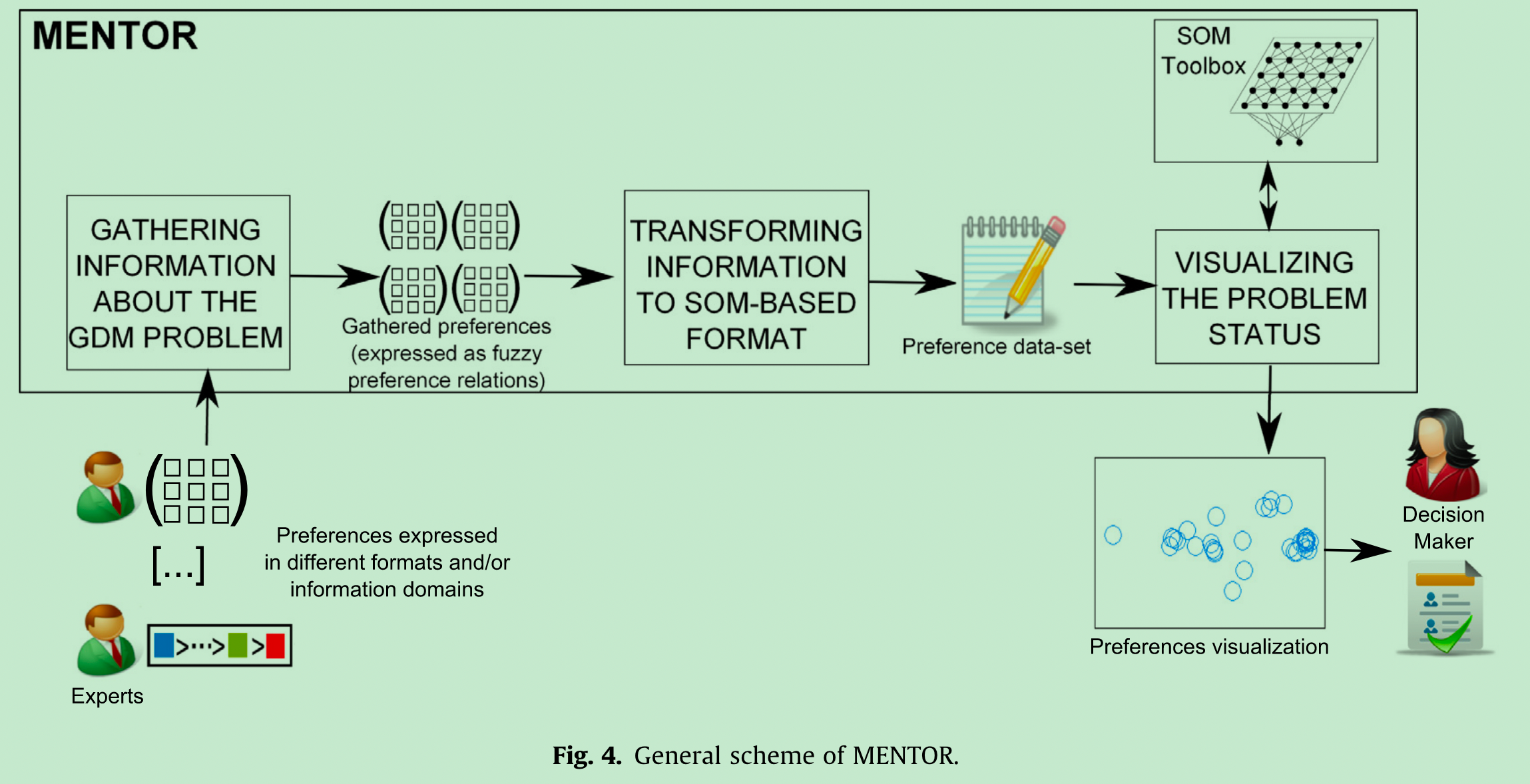
MENTOR: A graphical monitoring tool of preferences evolution in large-scale group decision making
- 期刊:Knowledge-Based Systems 2014
- 这篇文章做的事:把多个专家在决策上的偏好矩阵(n x n),通过SOM方法,投影成一个图片,以帮助决策者做出决定。
Towards Rigorously Designed Preference Visualizations for Group Decision Making
来源:
2020 IEEE Pacific Visualization Symposium (PacificVis)
本工作的定位:
结构化的决策过程和个人偏好建模尤其可以促进更富有成效的分析和讨论。InfoVis
解决方案有可能丰富这一过程,但只有少数工作尝试过,而且似乎都没有基于对用户需求和设计选项的全面理解。本文是解决这个gap的第一步。
我们开发并测试了一个原型,to support group-decision-making when decision makers express their preferences directly on the
alternatives
设定:
简单来说,本文针对的是多人对多个选项进行打分,然后决策者根据这些数据进行决策的group Decision。
这篇文章所做事情的顺序:
找GDM的场景(审稿人投票选最佳论文,等,Table2,Table 4)
不断细化需要什么样的任务(Table5, Table 6)
3.根据对这些任务的满足程度进行打分(Figure 4),来判断哪种图更适合进行表示,最后得出这样一个界面,可以以人来显示(左),也可以以项目来显示(右)
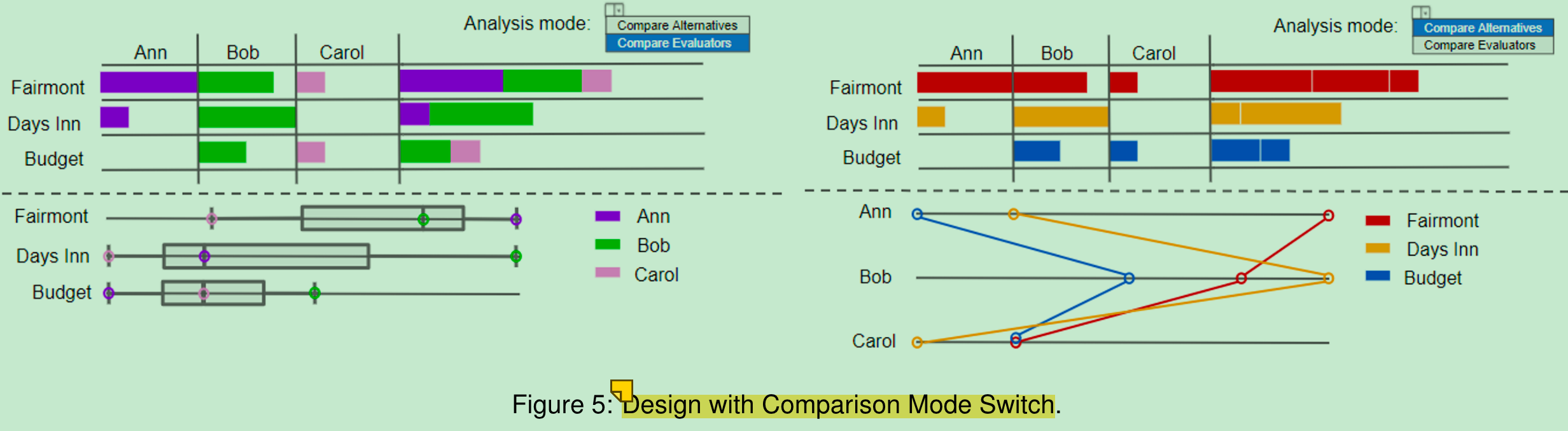
user case:
找了两个group Decision的样例,让里面的小组成员使用后,评价这个界面设计的各个环节(组成部分)
limitation and future work:
这种表示方法只适合小规模(参与者还指出,对于更大的场景,可视化将变得更难阅读;在不牺牲有效性的情况下解决可扩展性问题对于未来的工作很重要。)
要求使用者匿名,以更好决策。(意见异常的人可能会感到被迫与其他人保持一致,而匿名可以帮助抵消这种影响)
为方案提供额外的排序选项,例如按方差排序。(这与观察到的寻找使总分最大化 同时最小化分歧的替代方案的趋势相吻合。)
The Unmet Data Visualization Needs of Decision Makers within Organizations
来源: TVCG2021
这个帖子说的挺全的。这篇文章主要目的是:“强调将可视化设计从数据分析扩展到信息管理工具的必要性”。做的事主要是:review管理理论中的相关文献,报告一个实证调查和对决策人员的访谈结果,总结他们需要什么样的可视化(新的可视化工具所面临的挑战和机遇,包括权衡概述、基于场景的分析、询问工具、灵活的数据输入和协作支持)
DCPAIRS: A Pairs Plot Based Decision Support System
- 来源: EuroVis-19th EG/VGTC Conference on Visualization
- 这个挺有意思,拖动轴上的比例,对不同大学进行打分,给不同选项标记不同的标签,来决定申请哪个大学。